OpenAI gpt-audio-1.5 vs BibiGPT:2026 ポッドキャスト・長時間音声の要約にはどちらの音声 API を使うべき?
OpenAI の gpt-audio-1.5 は音声入力と TTS 出力を一つの呼び出しに統合。BibiGPT はポッドキャストと長時間音声の要約をエンドツーエンドで提供。使い分けと組合せパターンを整理しました。
OpenAI gpt-audio-1.5 vs BibiGPT:2026 ポッドキャスト・長時間音声の要約にはどちらの音声 API を使うべき?
OpenAI は gpt-audio-1.5 を Chat Completions における最高の音声入出力モデルと位置づけ、音声理解と TTS 応答を一つの呼び出しに統合しました。短ターンの音声エージェントを作るなら有力な初期選択です。しかし目的が「ポッドキャストの要約」「1時間以上の長時間音声理解」「中国語圏ユーザー向けの知識成果物」であるなら、BibiGPT はすでにそれらをプロダクト化しており、ゼロエンジニアリングで使えます。 本記事では OpenAI の公式ドキュメントに基づいて両者を比較し、移行・組み合わせのパターンを示します。
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
目次
- クイック比較:ポジショニング
- gpt-audio-1.5 にできること・できないこと
- BibiGPT がポッドキャスト・長時間音声で補完する領域
- API 移行コストとハイブリッドパターン
- FAQ:gpt-audio-1.5 vs BibiGPT
クイック比較:ポジショニング
コア回答: OpenAI gpt-audio-1.5 は、リアルタイム・会話型の音声エージェントを作る開発者向けの汎用音声 I/O モデルです。BibiGPT は消費者・クリエイター向けのプロダクトで、長時間音声/動画要約・字幕エクスポート・マインドマップ・AI 書き換え・マルチデバイスアプリを含みます。両者は代替関係ではなく、「基盤モデル」と「エンドツーエンド・アプリケーション」のレイヤー関係にあります。
| 項目 | OpenAI gpt-audio-1.5 | BibiGPT |
|---|---|---|
| ポジショニング | 汎用音声 I/O モデル(Chat Completions 音声入力+出力) | 消費者・クリエイター向け AI 音声/動画アシスタント |
| 入力長 | 短ターン対話に最適化;長時間音声は自前チャンク分割が必要 | 1時間以上のポッドキャスト・講義・会議に標準対応 |
| 中国語領域 | 汎用;中国語固有名詞の後処理は自前 | 中国語ポッドキャスト・Bilibili・講義に長期チューニング |
| 成果物 | テキスト + 音声応答 | 要約、SRT 字幕、マインドマップ、記事リライト、PPT、共有ポスター |
| エンジニアリング工数 | 取り込み・分割・保存・UI・課金まで自前構築 | リンク貼付けまたはファイルアップロード |
| 価格 | トークン/秒単位の API 課金 | サブスクリプション(Plus/Pro)+ チャージ |
| サーフェス | 自社構築次第 | Web + デスクトップ(macOS/Windows)+ モバイル + API + Agent Skill |
gpt-audio-1.5 にできること・できないこと
コア回答: OpenAI 開発者ドキュメント によれば、gpt-audio-1.5 は Chat Completions で現在最も優れた音声入出力モデルであり、一回の呼び出しで音声入力を受け取り音声またはテキストで応答します。低遅延音声エージェント、翻訳アシスタント、音声メモ用途に最適です。
できること:
- エンドツーエンドの音声 I/O — 「聞く→理解→回答→話す」を一回の呼び出しで処理、STT+LLM+TTS を自前で繋ぐ必要なし;
- 表現力のある TTS — OpenAI 次世代音声モデルの発表 によれば、新しい TTS は初めて「こう話して」という指示(例:「共感するカスタマーサポートのように」)を受け付け、感情表現のある音声体験を可能にします;
- リアルタイム音声エージェント — gpt-realtime と組み合わせてプロダクション級のリアルタイム対話・割り込み・ロールプレイが可能(OpenAI gpt-realtime 発表 参照)。
できないこと(または自前構築が必要):
- ポッドキャスト・講義・会議の知識成果物 — 汎用モデルなので、章立て要約+マインドマップ+タイムスタンプジャンプ字幕はくれません;
- YouTube/Bilibili/Apple Podcasts/小宇宙/TikTok のリンク解析 — URL 解析・ダウンロード・分割はエンジニアリング課題;
- 多言語記事リライト・共有カード・小紅書カバー — プロダクトレイヤーの機能であり API 範囲外;
- チャンネル登録・日次ダイジェスト・動画横断検索 などの長期運用機能。
BibiGPT がポッドキャスト・長時間音声で補完する領域
コア回答: BibiGPT は「長時間音声理解 + 成果物化 + マルチサーフェス配信」を即利用可能なプロダクトとして提供します。ポッドキャストのリンクを貼るだけで、約30秒で二人対話形式の音声・同期字幕・構造化要約が得られます。
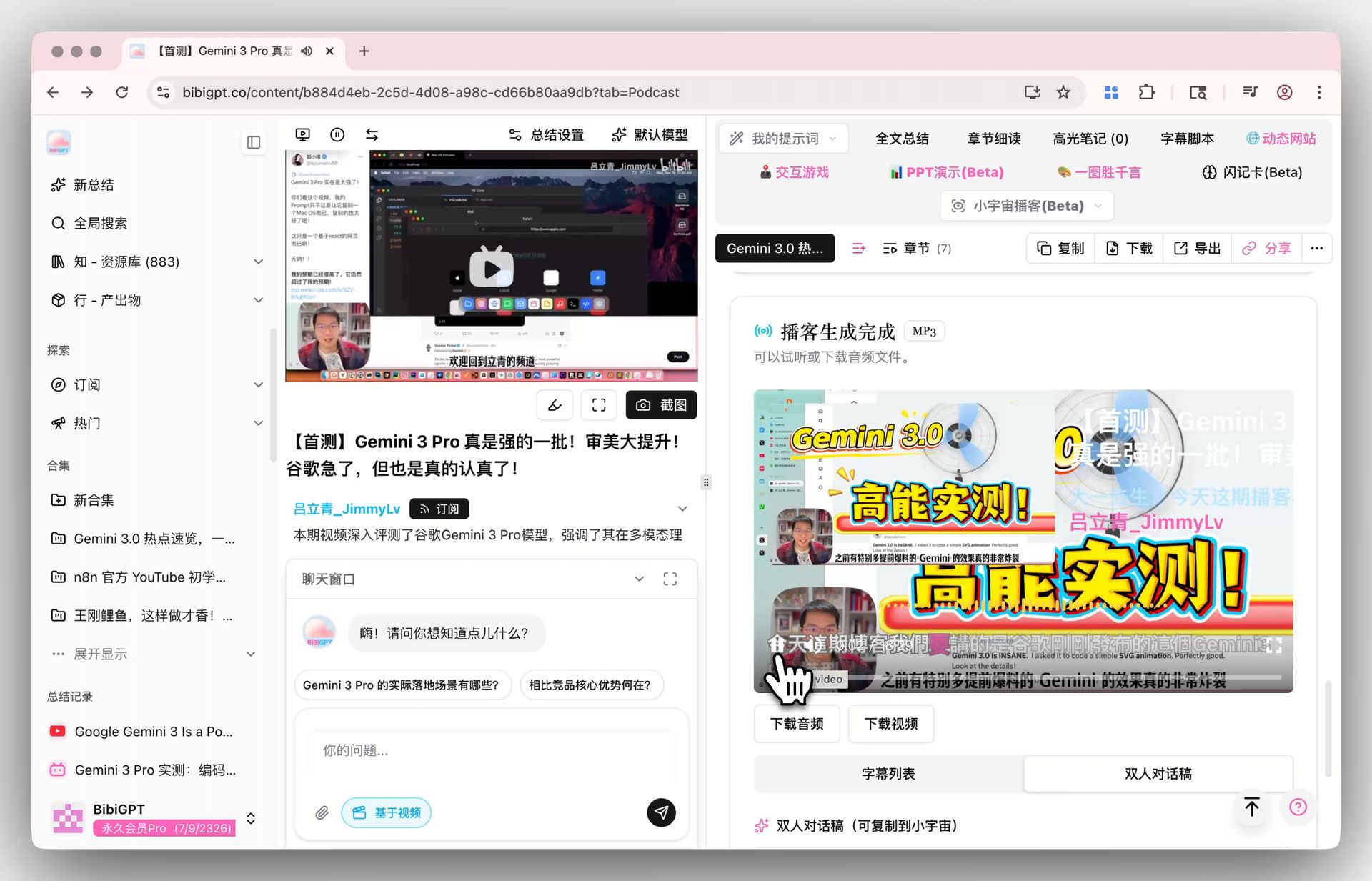 小宇宙ポッドキャスト生成
小宇宙ポッドキャスト生成
純粋な API で再現しようとするとコスト・工数が大きい代表的な3つの機能:
- 小宇宙ポッドキャスト生成 — 任意の動画を小宇宙風の二人対話音声(大一先生・Mizai 同学などの声の組み合わせ)に変換し、同時に字幕リスト・対話スクリプト・字幕付き動画を提供。単一ターン TTS より遥かに「コンテンツプロダクト」に近い体験です。詳しくは → AI ポッドキャスト文字起こしツール 2026。
- プロ級ポッドキャスト文字起こし — Whisper と最高峰の ElevenLabs Scribe エンジンを切り替え、自分の API キーを入力可能。専門ポッドキャスト・学術講義・業界インタビューに最適。
- マルチサーフェス連携ワークフロー — 同じ音声を Web・デスクトップ(macOS/Windows)・モバイルでハイライト、AI への追加質問、Notion/Obsidian への書き出し、そして AI 動画→記事 や 小紅書向けビジュアル パイプラインへの接続が可能。
AI Subtitle Extraction Preview
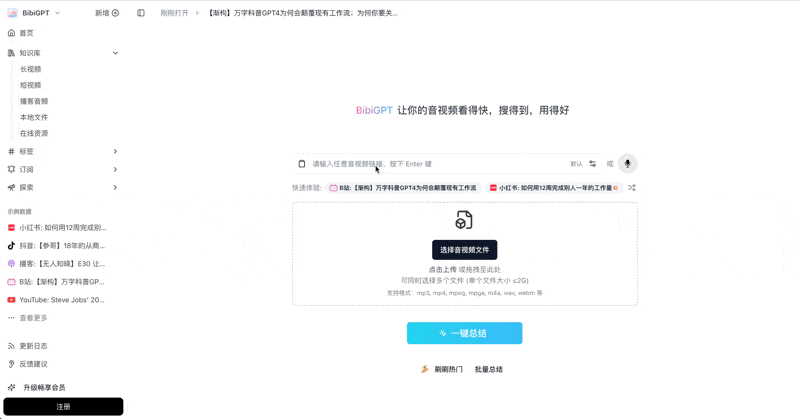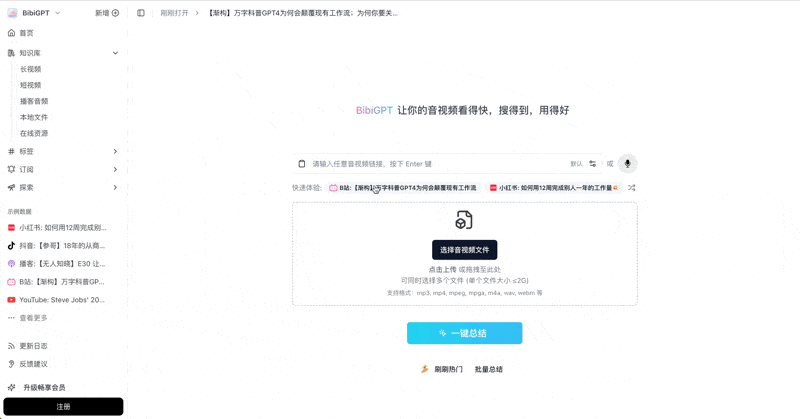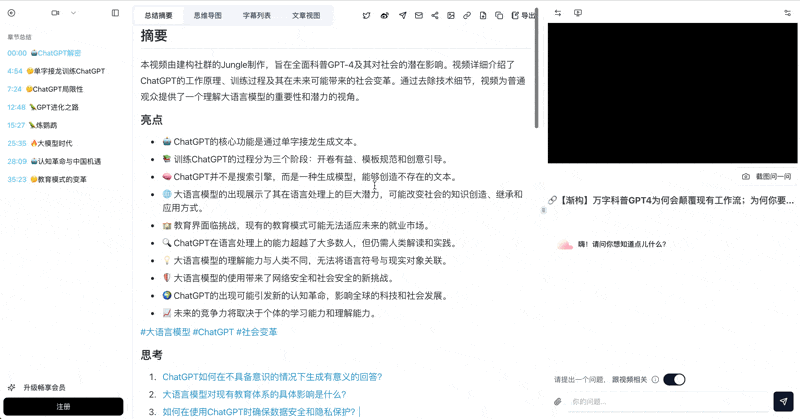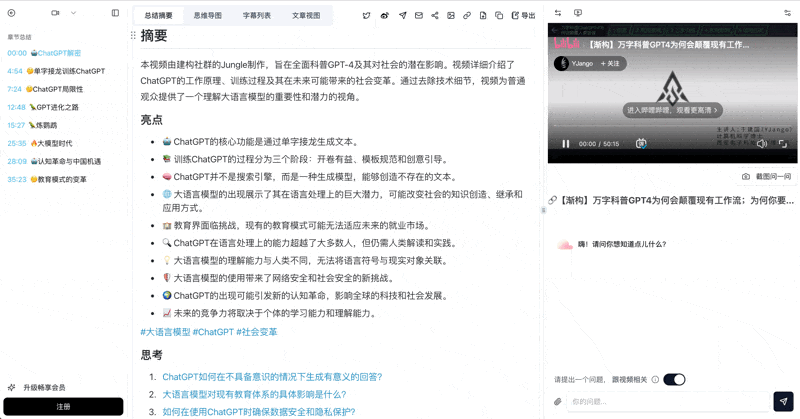
Bilibili: GPT-4ワークフロー革命
GPT-4がどのように仕事を変革するかを深掘りした科学解説動画。モデルの内部構造、学習段階、社会的影響を網羅。
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeAPI 移行コストとハイブリッドパターン
コア回答: 「gpt-audio-1.5 直結」と「BibiGPT」は競合ではなく補完関係です。音声理解と成果物レイヤーは BibiGPT に、リアルタイム音声対話は gpt-audio-1.5 に任せることで、全体コストとエンジニアリング負荷が大きく下がります。
既存の音声スタックを持つチームへの移行提案:
- ポッドキャスト/講義の要約パイプライン → 分割・ASR・要約・マインドマップ・記事リライトの5サブシステムを自前維持する代わりに BibiGPT API と Agent Skill を採用;
- 音声顧客対応・音声 NPC・音声入力 → OpenAI gpt-audio-1.5 + gpt-realtime を維持。BibiGPT はこのレイヤーには関与しない;
- 両方必要なチーム → gpt-audio-1.5 は「ユーザーの話を聞いて即応答」、BibiGPT は「長いコンテンツを聞いて知識成果物を生成」。
コスト観点:
- gpt-audio-1.5 はトークン/秒課金 → 短くて高並列の対話に有利;
- BibiGPT はサブスク+チャージ → 長時間音声・低頻度高価値の知識処理に有利;
- 「章立て要約 + DL 可能 SRT + 共有カード」を一括で必要とするなら、BibiGPT の方が一貫してコスパが良い。
FAQ:gpt-audio-1.5 vs BibiGPT
Q1:gpt-audio-1.5 は BibiGPT を置き換えますか?
A: いいえ。gpt-audio-1.5 は I/O レイヤーの開発者向けモデル、BibiGPT は消費者・クリエイター向けプロダクトレイヤーであり、下位に必要に応じて強力な音声モデルを取り込めます。
Q2:BibiGPT は gpt-audio-1.5 を採用しますか?
A: BibiGPT は OpenAI・Gemini・豆包・MiMo などマルチベンダー戦略を継続しています。gpt-audio-1.5 が中国語長時間音声・ポッドキャスト音声で明確な優位を示せば、選択可能モデルとして追加される可能性があります。
Q3:ポッドキャストを「タイムスタンプ付きテキスト+要約」にする最速の方法は?
A: ポッドキャスト URL を BibiGPT に貼り付ければ、30-60秒で構造化要約・SRT 字幕・インタラクティブなマインドマップが得られます。API コードは不要です。
Q4:gpt-audio-1.5 は中国語の口語・方言に対応していますか?
A: OpenAI ドキュメントによれば gpt-audio シリーズは多言語モデルですが、方言・中国語固有名詞の精度はサンプルテストが推奨されます。中国語コンテンツ消費シナリオでは BibiGPT の長年の字幕クリーニングと固有名詞辞書が強みです。
Q5:Agent 開発者です。エージェントに「動画を見る・ポッドキャストを聞く」能力を与えるには?
A: BibiGPT Agent Skill を参照してください。ポッドキャスト・動画理解能力を Agent-native ツールとしてパッケージ化しているため、Claude・ChatGPT などが「リンク貼付け→要約+字幕」を一回で実行できます。
今すぐAI効率的な学習の旅を始めましょう:
- 🌐 公式ウェブサイト: https://aitodo.co
- 📱 モバイルダウンロード: https://aitodo.co/app
- 💻 デスクトップダウンロード: https://aitodo.co/download/desktop
- ✨ より多くの機能を学ぶ: https://aitodo.co/features
BibiGPT チーム