Qwen3.5 Omni for Long Video Summary: 10-Hour Audio + 400-Second Video Native Processing vs BibiGPT (2026)
Alibaba's Qwen3.5 Omni natively handles 10+ hours of audio, 400+ seconds of 720p video, 113 languages, and 256k context. We break down the model specs and compare the end-user experience against BibiGPT — the AI video assistant that wraps models like this into a single paste-and-go flow.
Qwen3.5 Omni for Long Video Summary: 10-Hour Audio + 400-Second Video Native Processing vs BibiGPT (2026)
Table of Contents
- What Qwen3.5 Omni means for AI video summaries
- Qwen3.5 Omni tech specs at a glance
- From model capability to end-user experience
- BibiGPT × open multimodal models in practice
- Why BibiGPT still matters
- FAQ
- Wrap-up
What Qwen3.5 Omni means for AI video summaries
Quick answer: Alibaba released Qwen3.5 Omni on March 30, 2026 — arguably the strongest open-source fully multimodal model to date. It natively handles 10+ hours of audio, 400+ seconds of 720p video, 113 languages, and a 256k context window, pushing the "ceiling" of AI video summaries to frontier closed-model territory. For end users it is best understood as a foundation-layer upgrade: open-source models give AI assistants like BibiGPT more engines to choose from, translating into longer, more accurate, and more multilingual summaries at lower cost.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
If you've been frustrated the past year by "videos are too long for the AI," "non-English transcription is error-prone," or "summaries cut off after 30 minutes," Qwen3.5 Omni's generation of fully multimodal models is the direct remedy. This article dissects it from three angles: the model specs, what it takes to actually run it, and how products like BibiGPT turn it into a paste-and-go experience.
Qwen3.5 Omni tech specs at a glance
Quick answer: Qwen3.5 Omni's headline is "one model across text/image/audio/video," with native 10+ hour audio input, 400+ seconds of 720p video frame understanding, 256k token context, 113-language ASR, and Qwen's continued Thinker/Talker dual-brain architecture.
Based on Alibaba Qwen's official release coverage on MarkTechPost, the key specs are:
| Dimension | Spec | Why it matters for video summaries |
|---|---|---|
| Audio input | 10+ hours native | Full coverage of long podcasts, seminars, all-day lectures |
| Video input | 400+ seconds @ 720p | Frame-aware summaries that combine visuals and speech |
| Language ASR | 113 languages | Localization and cross-border meetings |
| Context | 256k tokens | Long video + citations + follow-up questions in one pass |
| Architecture | Thinker / Talker dual-brain | Reasoning and speech output decoupled; real-time interaction |
| License | Apache 2.0 | Commercial use, fine-tuning, and on-prem deployment |
For a broader benchmark across GPT, Claude, Gemini, and Qwen-series models, see our 2026 best AI audio/video summary tool review.
Why the open-source route matters
Qwen3.5 Omni landed the same week as InfiniteTalk AI, Gemma 4, Llama 4 Scout, and the Microsoft MAI family — the open multimodal space is now on a monthly release cadence. For users that translates into:
- Long-video summaries no longer require premium tiers — cheaper open bases let products lower pricing
- Non-English video finally works — 113 languages cover Spanish podcasts, Japanese lectures, Korean livestreams
- Privacy-sensitive use cases have options — Apache 2.0 allows on-prem, enterprise video doesn't have to leave the building
From model capability to end-user experience
Quick answer: Model specs are just the ceiling. Real end-user experience depends on engineering, platform adaptation, interaction design, and reliability. Qwen3.5 Omni's 256k context looks great in a paper, but between pasting a Bilibili link and getting a final summary there's URL parsing, subtitle extraction, hard-subtitle OCR, segmentation, prompt engineering, rendering, and export.
A production-grade AI video assistant solves at least seven engineering problems:
- URL parsing — YouTube / Bilibili / TikTok / Xiaohongshu / podcast apps each have their own URL and anti-scraping quirks
- Subtitle sourcing — use CC when available, run ASR when not, OCR for burned-in captions
- Long-content chunking — 256k sounds big, but 10 hours of audio will still saturate; you need smart chunking + summary merging
- Line-by-line translation — subtitle translation must keep timestamps, not lose them to wholesale paragraph translation
- Structured output — chapters / timestamps / summaries / mind maps require stable prompt engineering
- Export formats — SRT / Markdown / PDF / Notion / WeChat article each have their own conventions
- Reliability & cost — 10-hour podcasts are expensive; productization needs caching, queues, and priority
In other words, the frontier model alone isn't enough. Users don't want raw weights; they want a working product.
BibiGPT × open multimodal models in practice
Quick answer: BibiGPT is a leading AI audio/video assistant, trusted by over 1 million users with over 5 million AI summaries generated. Its role in a Qwen3.5 Omni-class world is to "wrap the frontier model into a paste-and-go experience" — users never see model names, chunking strategies, or deployment details.
From URL to structured summary
See BibiGPT's AI Summary in Action
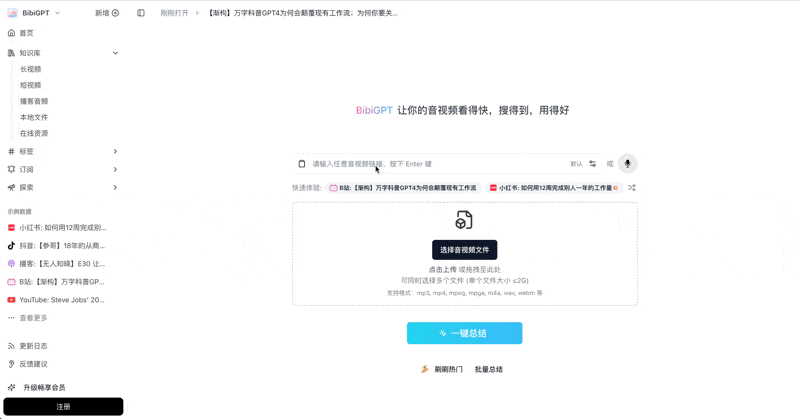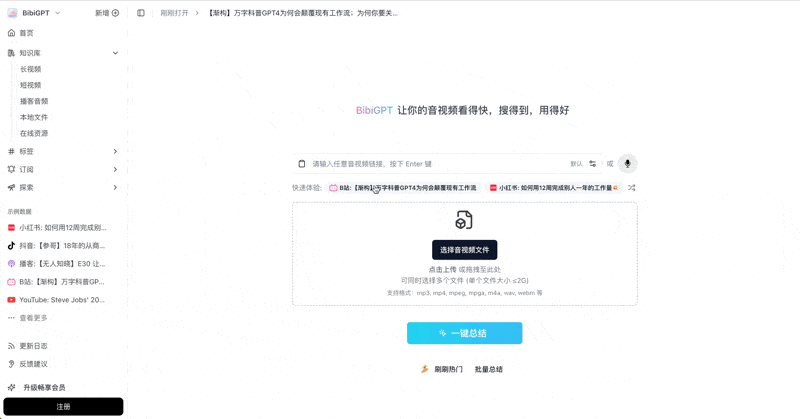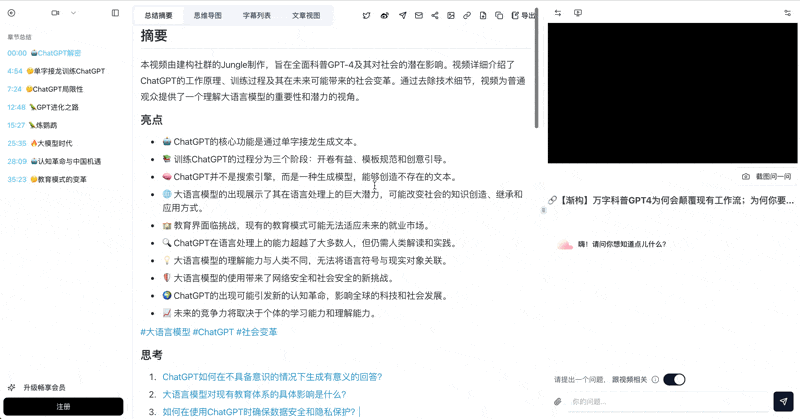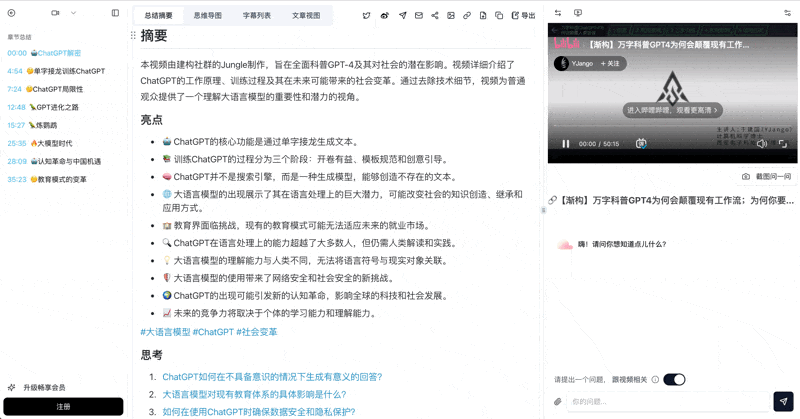
Bilibili: GPT-4 & Workflow Revolution
A deep-dive explainer on how GPT-4 transforms work, covering model internals, training stages, and the societal shift ahead.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeHow summarizing a 3-hour Bilibili tech talk actually looks:
- Open aitodo.co, paste the link
- The system auto-fetches captions (uses CC when available; ASR otherwise)
- Smart chunking → section summaries → chapter merging
- ~2 minutes later: full transcript, chaptered summary, mind map, AI chat with timestamps
The same flow works across platforms — Bilibili video summary, YouTube video summary, and podcast generation share the same pipeline.
What makes long-video UX actually work
Long audio/video is where Qwen3.5 Omni-class models shine, but "summarizing a 4-hour podcast without breaks" requires more than model context length:
- Smart subtitle segmentation — merges 174 choppy captions into 38 readable sentences, saving context
- Chapter deep-reading — integrates chapter summaries, AI polish, and captions in a focused reader
- AI chat with video — ask anything, with timestamp-traceable source citations
- Visual analysis — keyframe screenshots + content understanding for social cards, short-form videos, slides
 AI video to article output
AI video to article output
Why BibiGPT still matters
Quick answer: Qwen3.5 Omni is a foundation model; BibiGPT is a product experience. They are complementary, not competing. BibiGPT's differentiation spans four layers: 30+ platform coverage, complete subtitle pipeline, depth in Chinese creator workflows, and deep integration with Notion/Obsidian-style knowledge stacks.
1. 30+ platforms & anti-scraping engineering
Open models don't solve Bilibili/Xiaohongshu/Douyin scraping. BibiGPT invests in platform adapters across 30+ video/audio sources — that's engineering value you can't reproduce by downloading Qwen3.5 Omni weights.
2. Complete subtitle pipeline
Extraction, translation, segmentation, hard-subtitle OCR, and export form a closed loop. Not just "give me a summary" but "captions + translation + SRT + AI rewrite in one go," saving 5-8 manual steps compared to naked model calls.
3. Creator-focused workflows
WeChat article rewriting, Xiaohongshu promo images, short-video generation — these are high-frequency needs for creators. Raw models don't solve "export to WeChat." BibiGPT's AI video to article targets the creator's second-distribution workflow directly.
4. Deep notes integration
Notion, Obsidian, Readwise, Cubox — BibiGPT ships multiple note-sync connectors. Paste a link; the summary lands in your personal knowledge base. That ecosystem value isn't something raw model calls can offer.
FAQ
Q1: Is Qwen3.5 Omni better than GPT-5 or Gemini 3? A: In the "open fully-multimodal" category, Qwen3.5 Omni is arguably the strongest option today, with 10-hour audio and 113-language ASR competitive with frontier closed models. For head-to-head closed-model comparisons see NotebookLM vs BibiGPT.
Q2: Can I run video summaries with Qwen3.5 Omni myself? A: Yes — Apache 2.0 allows commercial and on-prem use. But you still have to solve GPU costs, URL parsing, subtitle sourcing, long-video chunking, and structured output. If you don't have that engineering, packaged products like BibiGPT are a better value.
Q3: Does BibiGPT use Qwen3.5 Omni under the hood? A: BibiGPT selects models dynamically based on scene and cost. The principle is "give users the fastest, most reliable, most accurate result" — specific backends are transparent to the user.
Q4: Can you really summarize 10 hours of audio in one pass? A: The model supports it on paper; real UX depends on implementation. BibiGPT uses smart chunking + summary merging to keep 3-5 hour podcasts at a stable 2-3 minutes end-to-end. For 10-hour content we recommend chunking the upload.
Q5: Will open models replace products like BibiGPT? A: Quite the opposite — stronger open models make the productization layer more valuable. Most users don't want weights; they want paste-and-go. Better models make BibiGPT faster, more accurate, and cheaper, not obsolete.
Wrap-up
Qwen3.5 Omni signals that AI video summarization is graduating from a luxury to a utility. The model ceiling keeps rising, but for end users the decisive factor is still "can I paste a link and get a result" — that's the productization layer.
If you're a researcher, creator, student, or knowledge worker, the highest-leverage move is not chasing open weights — it's using a polished AI video assistant:
- 🎬 Visit aitodo.co and paste any video link
- 💬 Need batch API access? Check out the BibiGPT Agent Skill overview
- 🧠 Bring your video knowledge into Notion / Obsidian through the built-in sync connectors
BibiGPT Team