OpenAI gpt-audio-1.5 vs BibiGPT in 2026: Which Audio API Should You Use for Podcasts and Long-Form Audio?
OpenAI's gpt-audio-1.5 unifies audio input and TTS output in one call. BibiGPT covers podcast and long-form audio summarization end to end. Here's when to use each, and how to combine them.
OpenAI gpt-audio-1.5 vs BibiGPT in 2026: Which Audio API Should You Use for Podcasts and Long-Form Audio?
OpenAI now positions gpt-audio-1.5 as its best voice model for audio-in/audio-out Chat Completions, unifying speech understanding and TTS in a single call. If you are building a short-turn voice agent, that is a great default. If your real goal is summarizing podcasts, handling hour-long audio, or shipping knowledge artifacts to Chinese-speaking users, BibiGPT already packages that as a product — with no engineering to assemble. This post compares both approaches based on OpenAI's own documentation and gives you migration and hybrid patterns.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
Table of Contents
- Quick Comparison: Positioning
- What gpt-audio-1.5 Can and Cannot Do
- Where BibiGPT Complements It on Podcasts and Long Audio
- API Migration Cost and Hybrid Patterns
- FAQ: gpt-audio-1.5 vs BibiGPT
Quick Comparison: Positioning
Core answer: OpenAI gpt-audio-1.5 is a general-purpose voice I/O model for developers building realtime or conversational voice agents. BibiGPT is a product for consumers and creators — long-form audio/video summarization, subtitle exports, mindmaps, AI rewrites, and multi-platform apps. They are not alternatives; they stack as "foundation model" and "end-to-end application".
| Dimension | OpenAI gpt-audio-1.5 | BibiGPT |
|---|---|---|
| Positioning | General voice I/O model (audio input + output in Chat Completions) | AI audio/video assistant product for consumers and creators |
| Input length | Optimized for short-turn dialogue; long audio requires your own chunking | Handles 1+ hour podcasts, lectures, meetings out of the box |
| Chinese-market coverage | General-purpose; Chinese named-entity polishing is on you | Years of domain tuning for Chinese podcasts, Bilibili, lectures |
| Outputs | Text + speech response | Summaries, SRT subtitles, mindmaps, article rewrites, PPT, share posters |
| Engineering cost | You build ingestion, chunking, storage, UI, billing | Paste a link, upload a file, done |
| Pricing | Per-token / per-second API pricing | Subscription (Plus/Pro) + top-ups |
| Surfaces | Whatever you build | Web + desktop (macOS/Windows) + mobile + API + Agent Skill |
What gpt-audio-1.5 Can and Cannot Do
Core answer: Per OpenAI's developer docs, gpt-audio-1.5 is the best voice model today for audio-in / audio-out Chat Completions, accepting audio input and returning audio or text in a single call. It is the natural pick for low-latency voice agents, translation assistants, and voice notes.
What it does well:
- End-to-end audio I/O — one call covers "listen → understand → answer → speak" without gluing STT + LLM + TTS yourself;
- Expressive TTS — according to OpenAI's next-gen audio models announcement, the new TTS for the first time accepts "speak this way" instructions (e.g. "talk like a sympathetic customer-service agent"), enabling emotional voice experiences;
- Realtime voice agents — combined with gpt-realtime, it powers production-grade realtime voice conversations, barge-in, and role play (see OpenAI's gpt-realtime announcement).
What it does not do (or requires you to build):
- Podcast / lecture / meeting knowledge artifacts — gpt-audio-1.5 is a general model; it does not hand you chaptered summaries + mindmap + clickable-timestamp transcripts;
- Link ingestion for YouTube / Bilibili / Apple Podcasts / Xiaoyuzhou / TikTok — parsing URLs, downloading, chunking and uploading are your engineering problem;
- Multilingual article rewrite, share cards, Xiaohongshu covers — product-layer capabilities, not API-level;
- Channel subscriptions, daily digests, cross-video search and other long-running operator features.
Where BibiGPT Complements It on Podcasts and Long Audio
Core answer: BibiGPT ships long-audio understanding, artifact generation, and multi-surface distribution as an out-of-the-box product. Drop a podcast link, and in about 30 seconds you get a two-host dialogue-style podcast render, synced captions, and a structured summary.
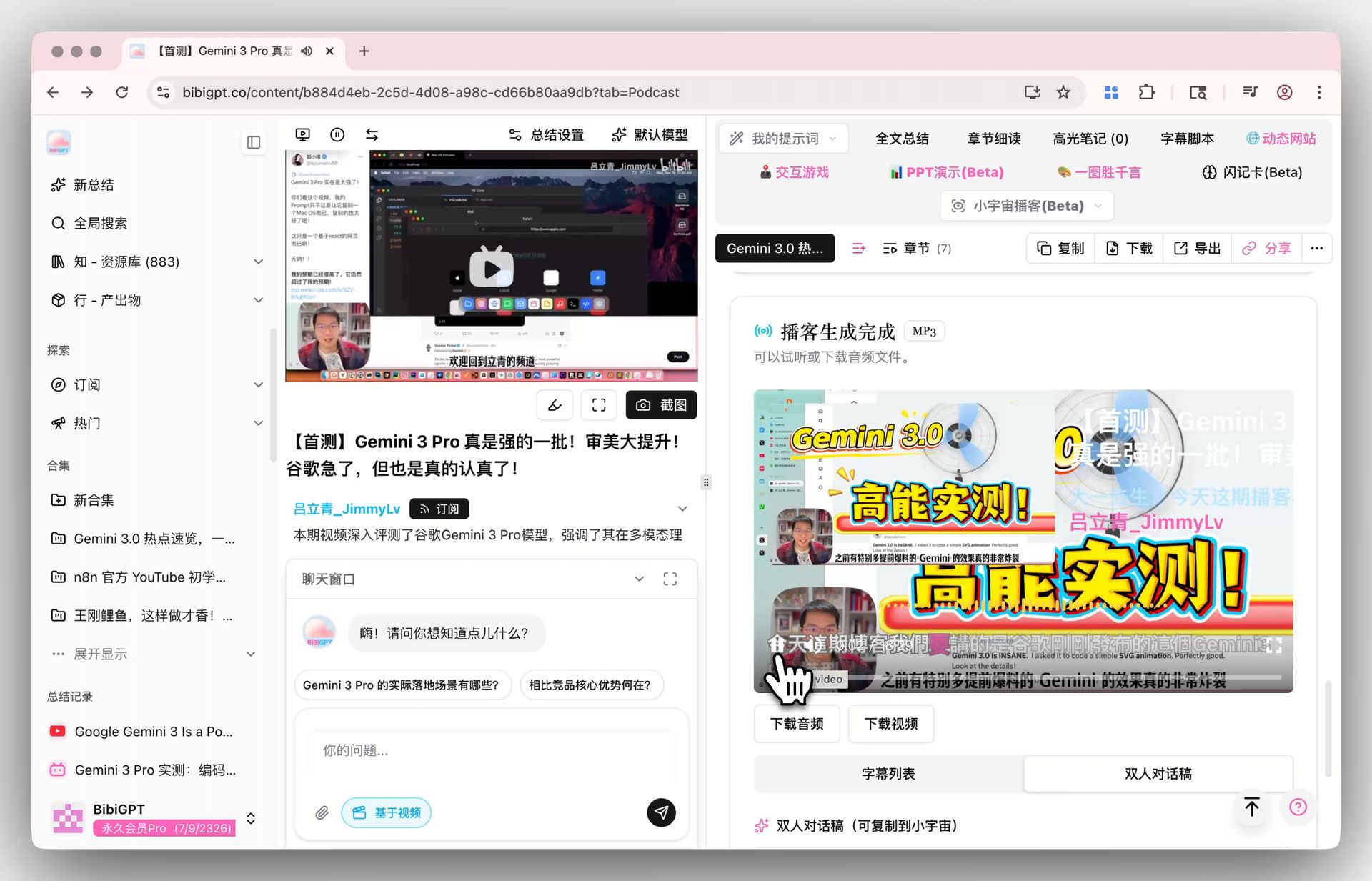 Xiaoyuzhou podcast generation
Xiaoyuzhou podcast generation
Three capabilities where rolling a pure-API solution is expensive or impractical:
- Xiaoyuzhou podcast generation — turn any video into a Xiaoyuzhou-style two-host dialogue audio (voice combos like "Daiyi Xiansheng" and "Mizai Tongxue"), with synced captions, dialogue scripts, and subtitled video downloads. That is closer to a "content product" than any single-turn TTS call. Learn more → AI podcast transcription tools 2026.
- Pro-grade podcast transcription — pick between Whisper and top-tier ElevenLabs Scribe engines, with your own API key, for pro podcasts, academic talks, and industry interviews.
- Multi-surface workflow — the same audio can be highlighted, queried, exported to Notion/Obsidian, and pushed into downstream AI video-to-article or Xiaohongshu-style visual flows on web, desktop (macOS/Windows), and mobile.
AI Subtitle Extraction Preview
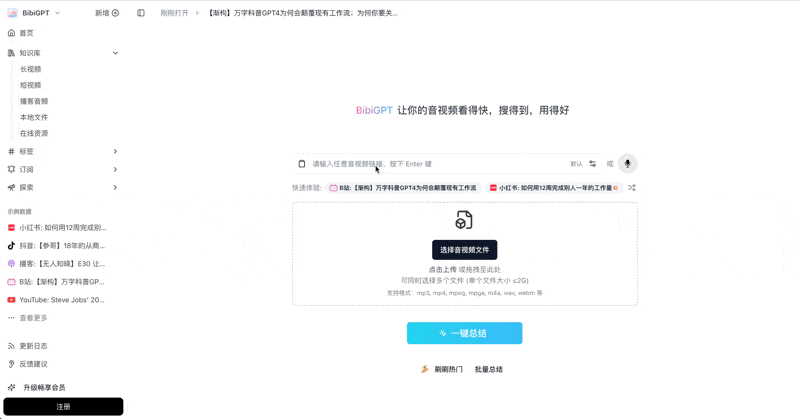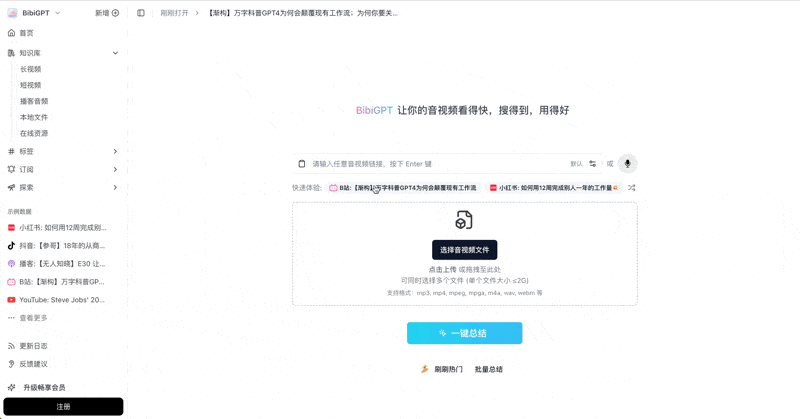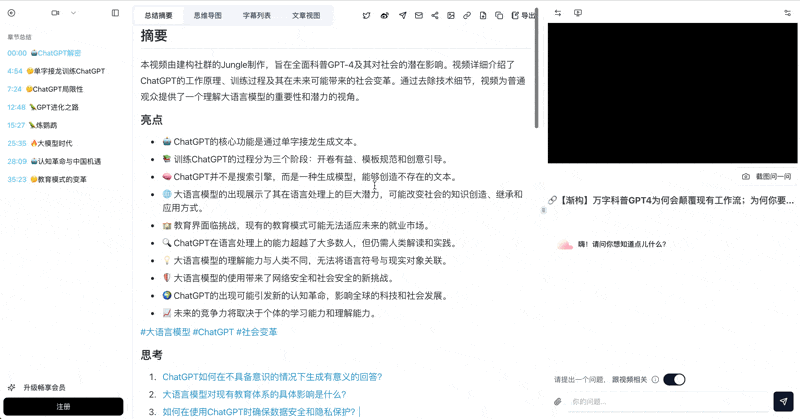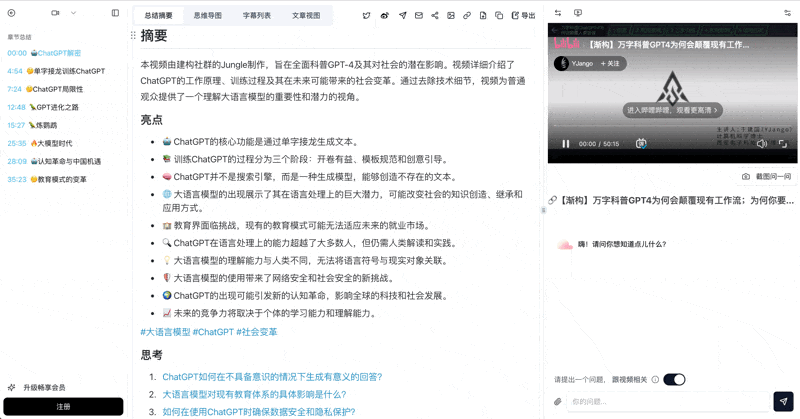
Bilibili: GPT-4 & Workflow Revolution
A deep-dive explainer on how GPT-4 transforms work, covering model internals, training stages, and the societal shift ahead.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeAPI Migration Cost and Hybrid Patterns
Core answer: "Direct gpt-audio-1.5" and "BibiGPT" are complements, not competitors. Let BibiGPT own the audio-understanding-and-artifact layer, let gpt-audio-1.5 own the realtime conversation layer, and your cost and engineering load drop significantly.
Migration guidance for teams with an existing audio stack:
- Podcast / lecture summarization pipelines → switch to BibiGPT's API and Agent Skill rather than maintain in-house chunking, ASR, summarization, mindmap, and article-rewrite subsystems;
- Voice agents, voice NPCs, voice input methods → keep OpenAI gpt-audio-1.5 + gpt-realtime; BibiGPT does not operate in that layer;
- Teams with both needs → gpt-audio-1.5 handles "listen to the user and respond instantly"; BibiGPT handles "listen to long content and produce knowledge artifacts".
Cost framing:
- gpt-audio-1.5 bills by tokens/seconds — great for short, high-concurrency dialogues;
- BibiGPT bills via subscription + top-ups — great for long audio and high-value knowledge workflows;
- When your output is a "chaptered summary + downloadable SRT + share card", BibiGPT ships all of it from a single action — consistently cheaper than stitching 3-5 APIs.
FAQ: gpt-audio-1.5 vs BibiGPT
Q1: Will gpt-audio-1.5 replace BibiGPT?
A: No. gpt-audio-1.5 is a developer-facing model at the I/O layer. BibiGPT is a product-layer platform for consumers and creators, covering discovery, summarization, repurposing, and cross-surface usage — and it can swap in stronger audio models underneath as needed.
Q2: Will BibiGPT adopt gpt-audio-1.5?
A: BibiGPT has long maintained a multi-vendor strategy (OpenAI, Gemini, Doubao, MiMo, etc.). If gpt-audio-1.5 proves clearly better on Chinese long-form audio and spoken podcasts, expect it to enter the selectable model list.
Q3: I just want "one podcast episode → timestamped transcript + summary" — what is the fastest path?
A: Paste the podcast URL into BibiGPT, wait 30-60 seconds, and you get a structured summary, SRT subtitles, and an interactive mindmap — no API code required.
Q4: Does gpt-audio-1.5 handle Chinese speech and dialects?
A: Per OpenAI's docs, the gpt-audio family is multilingual; however, dialects and Chinese named-entity accuracy still warrant sample-based testing. For Chinese consumption scenarios, BibiGPT's years of subtitle cleanup and named-entity lists give you a stronger baseline.
Q5: I am an Agent developer — how can I give my agent "watch video / listen to podcast" capability?
A: Check BibiGPT Agent Skill. It packages BibiGPT's podcast/video understanding as Agent-native tools, so Claude/ChatGPT/others can go from "paste link" to "summary + subtitles" in one call.
Start your AI efficient learning journey now:
- 🌐 Official Website: https://aitodo.co
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Learn More Features: https://aitodo.co/features
BibiGPT Team