NotebookLM × Google Classroom 深度解读:教师如何构建视频知识库(2026 最新对比 BibiGPT)
2026-04-06 起 Google 为 Education Plus 教师账号逐步推出 NotebookLM × Google Classroom 集成与更高配额。本文从教师课堂视角拆解三大变化,并对比 BibiGPT 视频知识库工作流。
NotebookLM × Google Classroom 深度解读:教师如何构建视频知识库(2026 最新对比 BibiGPT)
截至 2026-04-24:Google 已经在 Workspace 官方博客确认,从 2026-04-06 起向 Education Plus 以及 Teaching and Learning 附加版的机构分阶段推送 NotebookLM 扩展能力,核心包括三栏布局(Sources / Chat / Studio)、Studio 内容工厂、以及与 Google Classroom 的直接打通。对于每天要面对几十节课视频、几百份讲义的老师来说,这是过去三年里影响最直接的一次更新(来源:Google Workspace Updates)。
本文聚焦教师与教育工作者角色,和之前两篇分别从「三栏布局」和「Gemini App 集成」角度切入的分析不同——这次我们只谈一个问题:Classroom 集成给课堂带来了什么,以及 BibiGPT 的视频知识库工作流如何和它搭配使用。
一、背景:Classroom 集成的三条时间轴
Google 这次面向教育市场的更新并不是一口气推出,而是分三段节奏:
- 2026-04-06:Education Plus 用户开始看到 NotebookLM 三栏布局、Studio 内容工厂,以及 Classroom 作为 Source 的接入入口。
- 2026-04-中:Teaching and Learning 附加版机构陆续获得相同权限,但配额(每天可生成 Audio Overview 次数、Notebook 上限)略低。
- 2026-04-末:Classroom 反向导入支持——老师在 Classroom 里发布作业时,可以直接嵌入 NotebookLM notebook 作为学生参考资料。
对比此前(2024–2025 年)教师只能把课堂录播拉进 NotebookLM,然后再手动分享链接给学生,现在Classroom 的班级名单、课程资料、作业可以被 NotebookLM 作为 Source 直接读取,AI 回答时会引用具体讲义页码或视频时间戳。这是"课件级联动"而不是"文件级联动"。
二、深度分析:对课堂场景的三重影响
1. 技术影响:Source 语料突破机构墙
过去 NotebookLM 的瓶颈在于 Source 只能是手动上传的 PDF、YouTube 链接、或粘贴文本。现在 Classroom 作为一级 Source,意味着一门课积累两年的讲义、视频、作业反馈会变成 NotebookLM 可以跨学期检索的单一知识库。老师换学期复用课件的成本从"整理文件夹"降到"选一个 Classroom 班级"。
2. 市场影响:教育机构采购决策被重写
对学校 IT 采购方而言,Education Plus 本身并不便宜,但现在它附带了一套自建型 AI 教学助理,这让 Google 有能力和 Canvas、Blackboard、Moodle 等 LMS 老牌厂商的 AI 插件直接竞争。Education Plus 的续约谈判桌上,"NotebookLM Classroom 联动"会成为对比项。
3. 生态影响:第三方视频工具的定位变化
值得注意的是,NotebookLM 的 Classroom 集成目前只覆盖 Classroom 内的资源(Google Drive 文档、YouTube 链接)。外部视频平台(B 站、抖音、小红书、播客)依然不在 Source 范围内。这让像 BibiGPT 这样的第三方视频知识库工具不是被替代,而是承担了"把外部视频喂给 NotebookLM"的中间层角色。
三、对 BibiGPT 用户的实际意义(分角色)
中小学教师
你用 BibiGPT 总结一节优质公开课(B 站、YouTube)→ 导出 PDF/Markdown → 上传进 Classroom → NotebookLM 自动吸收。这样原本 Classroom AI 够不到的外部优质教学资源,也能进入学生的 AI 答疑入口。
高校教师与助教
你把一学期 16 周的课堂录播(校内录播系统、B 站公开课)用 BibiGPT 批量转成结构化笔记和章节时间戳,然后通过 Obsidian 自动入库做二次备课。Classroom 集成让你可以把同一份备课笔记同步推给学生,形成"老师备课库 + 学生答疑库"两层知识库结构。
教育内容创作者 / 自媒体
做网课的创作者经常被追问"你这节课里 XX 概念是怎么讲的"。用 BibiGPT 给每节课生成带时间戳的章节笔记 + AI 对话追问入口,放在你的网站或 Classroom 侧边栏,可以把"被学生反复追问"的时间成本压下去。
四、BibiGPT 实战搭配:把外部视频喂进 NotebookLM × Classroom
这是本文最有实际价值的部分——Classroom 集成不能直接读 B 站视频,而这正是 BibiGPT 的主战场。下面给出一个完整工作流。
步骤 1:一键把外部视频变成结构化文本
在 bibigpt.co 粘贴任意 B 站 / YouTube / 小宇宙播客链接 → 10 秒内得到章节时间戳、AI 总结、字幕全文。
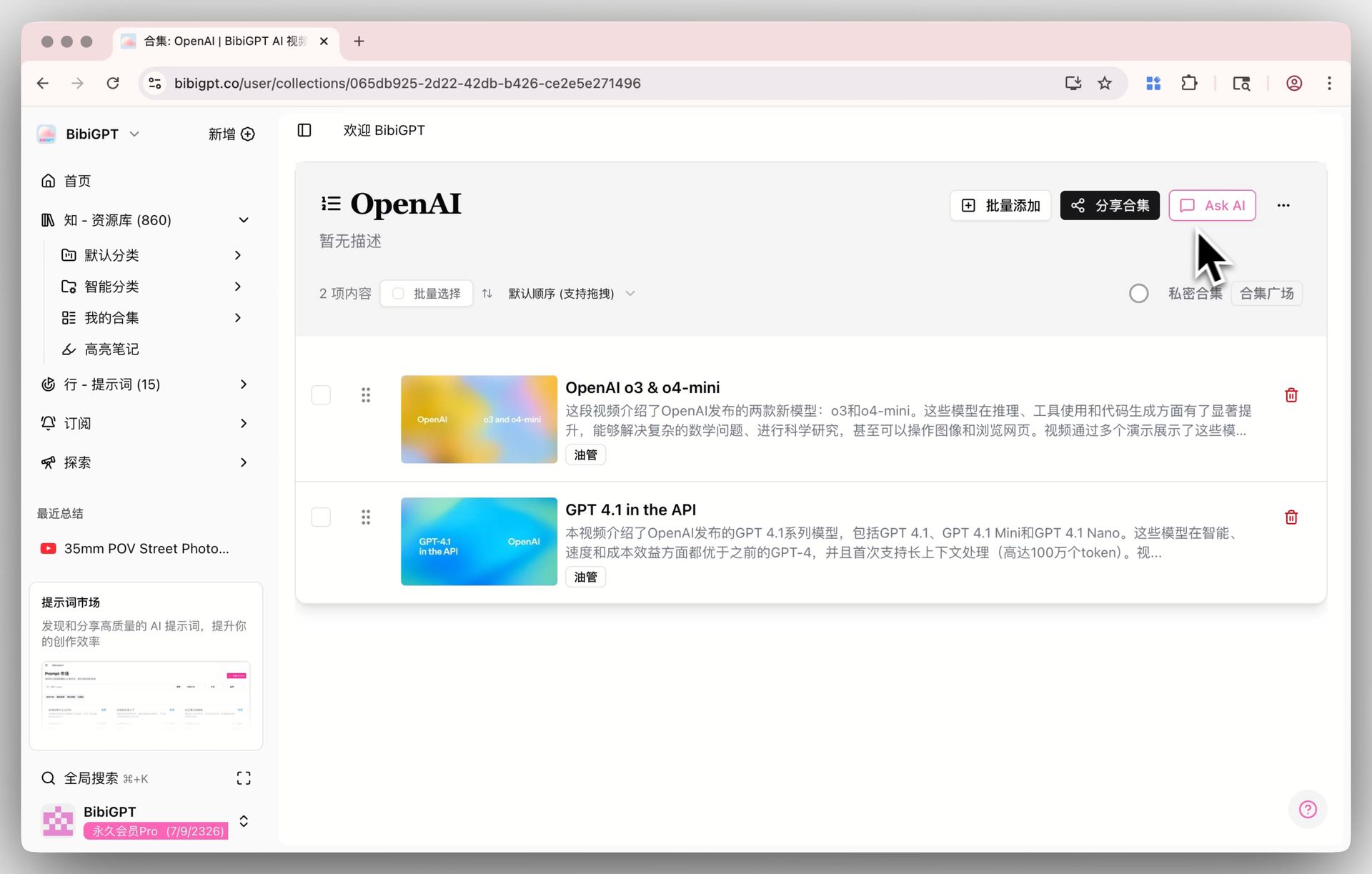 askai 入口
askai 入口
步骤 2:按课程主题归入合集
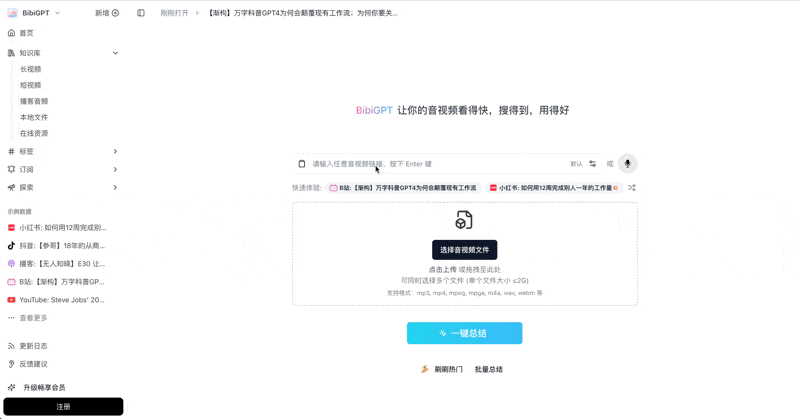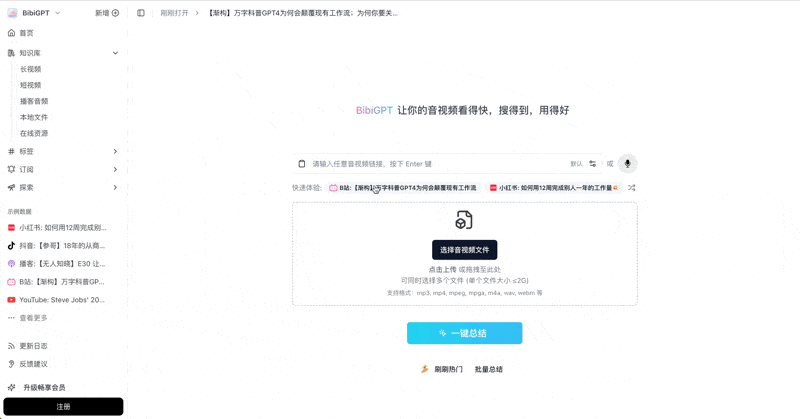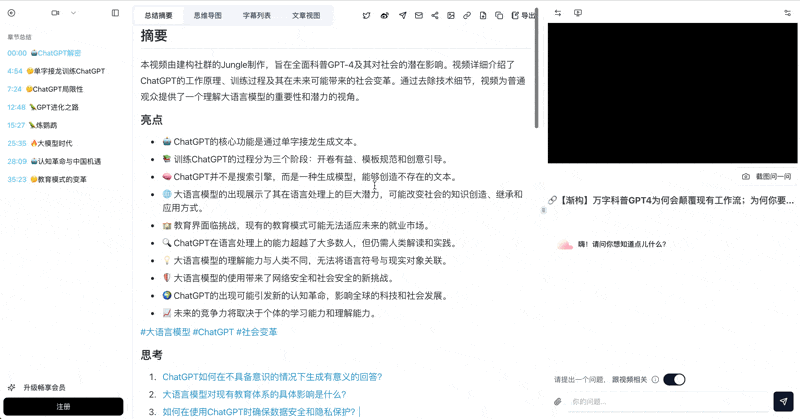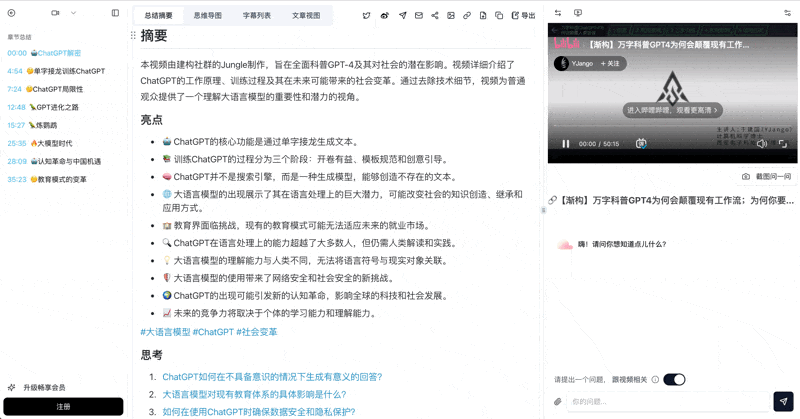
把一门课涉及的多个视频收纳进一个 BibiGPT 合集。合集具备跨视频 AI 对话能力,你和学生都能直接问"这门课里 XX 概念的几种解释"。
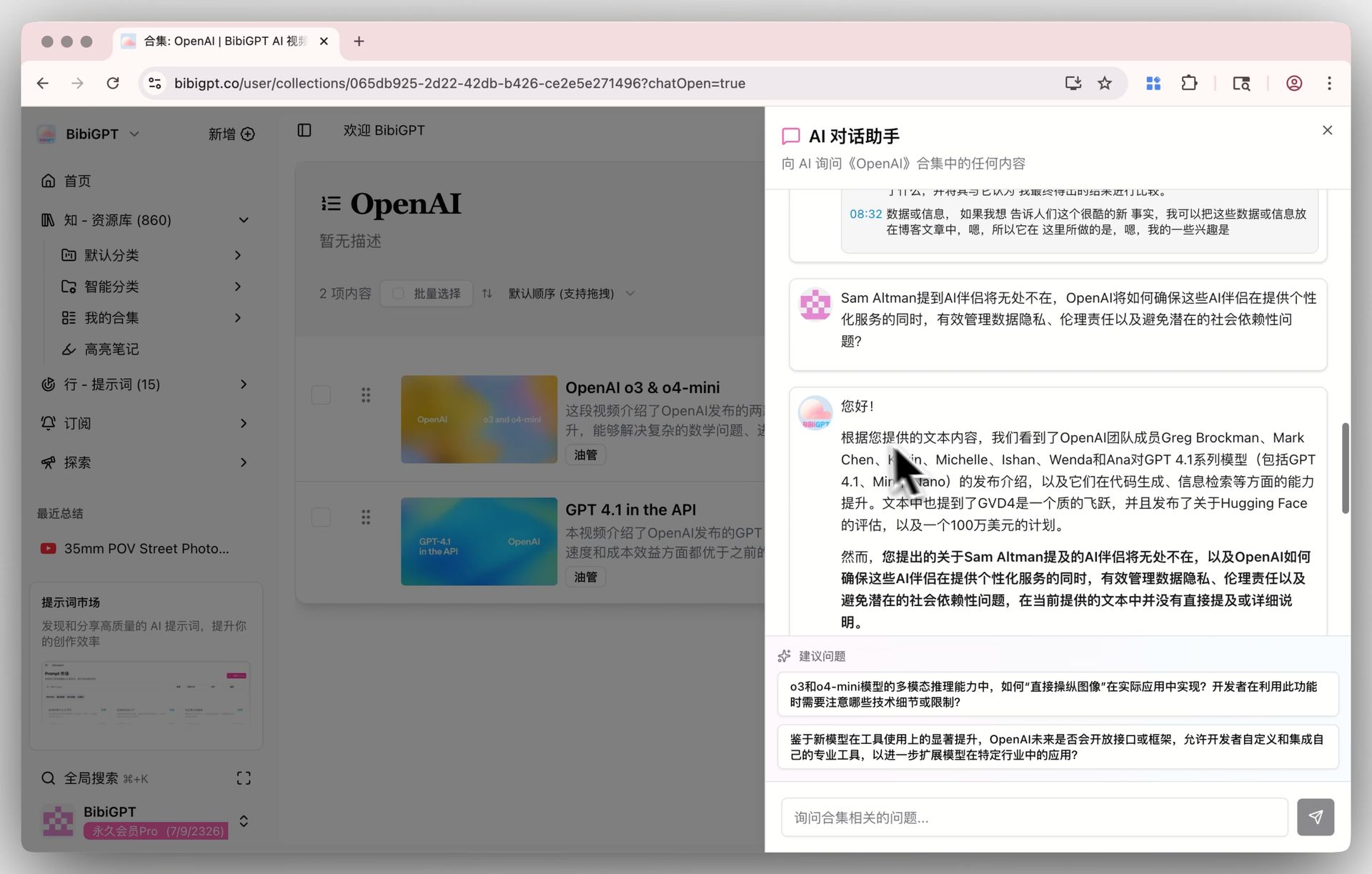 合集 AI 对话细节
合集 AI 对话细节
步骤 3:用自定义提示词生成教案雏形
BibiGPT 的「自定义提示词总结」允许你用自己的教学提示词(比如"按布鲁姆分类学分层提问")一键再生成。老师端的备课效率比手动整理提高至少一个量级。
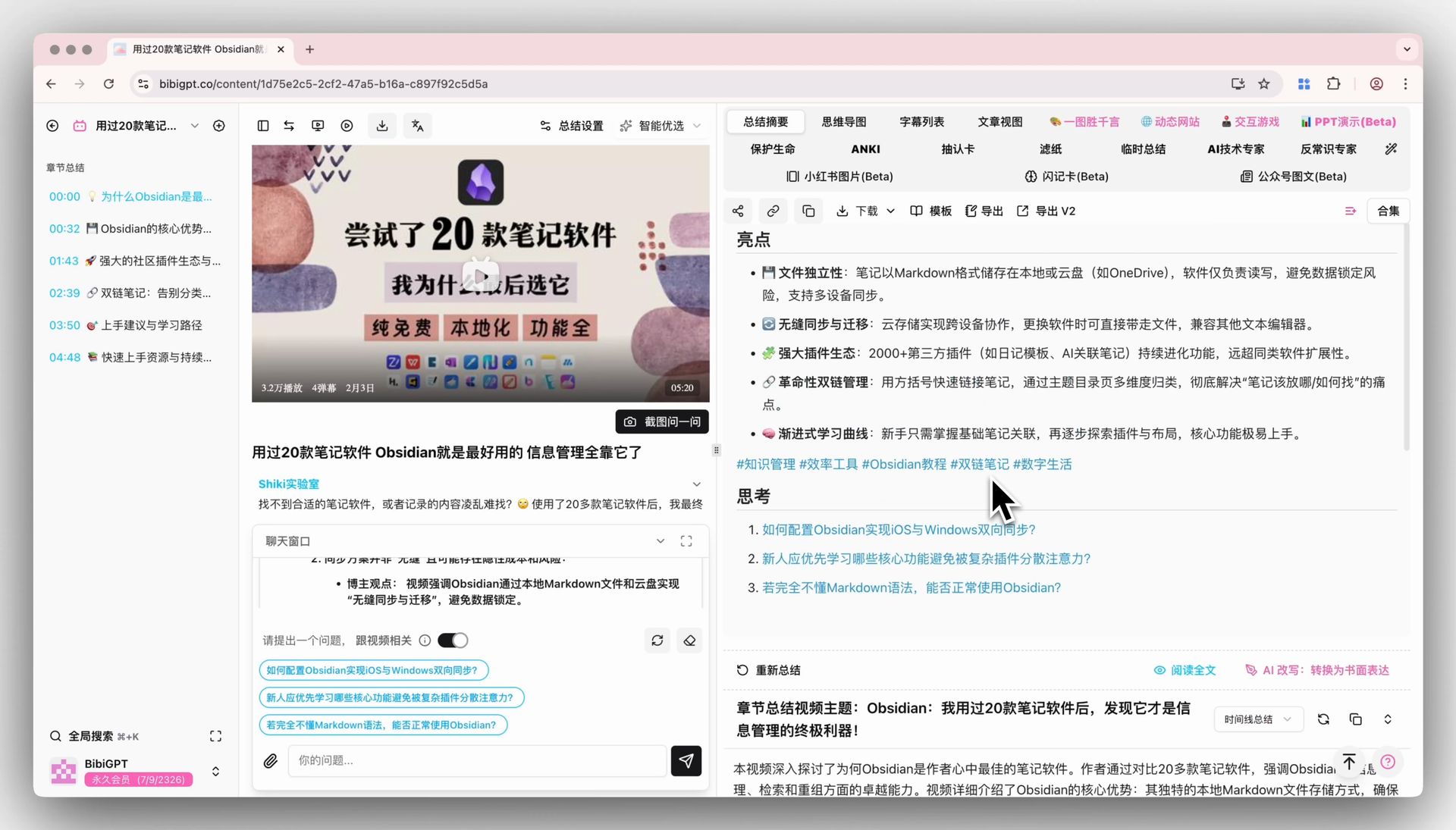 自定义提示词总结
自定义提示词总结
步骤 4:导出到 Obsidian 或直接丢进 Classroom
桌面客户端可以总结完成后自动保存到 Obsidian Vault 本地路径,备课笔记即刻入库。需要分发给学生时,从 Obsidian 导出 PDF / Markdown 再上传到 Classroom,NotebookLM 会吸收进 Source。
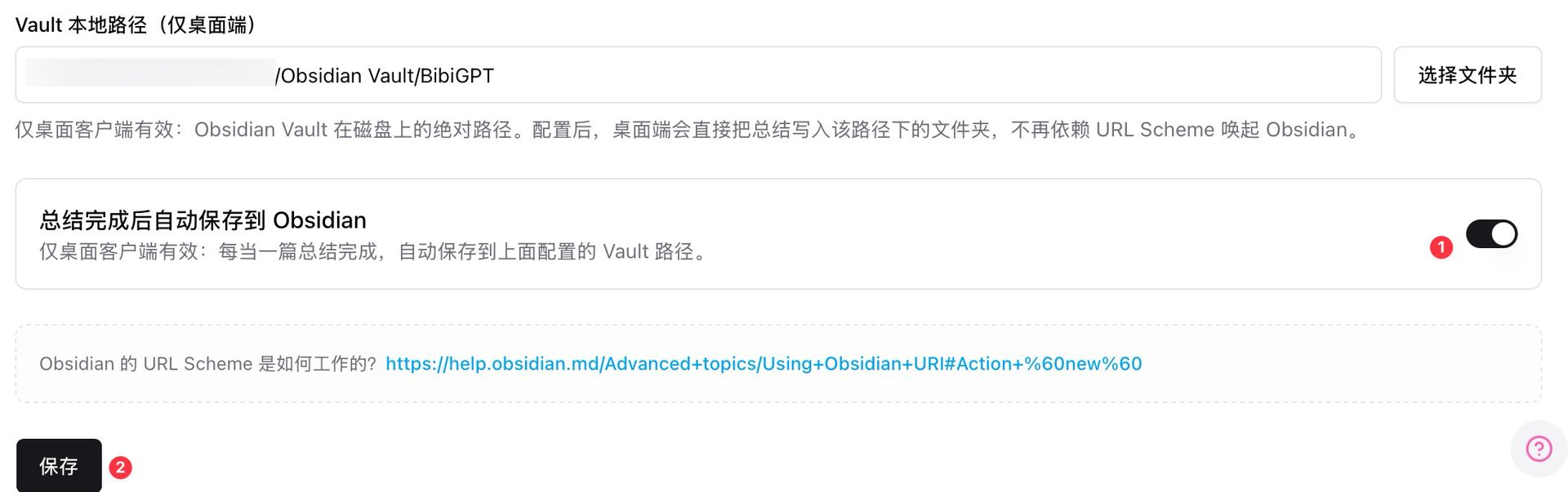 Obsidian 自动保存
Obsidian 自动保存
步骤 5:让 NotebookLM 和 BibiGPT 各司其职
- NotebookLM:充当班级共享层,学生问答由它承担,引用学校讲义和 Classroom 材料。
- BibiGPT:充当教师生产层,处理外部视频、合集追问、个性化提示词、Obsidian/飞书/语雀同步。
两个工具之间不是替代关系,是上下游关系。
五、前景预测:三个趋势判断
- Classroom 集成会继续扩展到学生侧工具。当前主要惠及教师账号,2026 下半年大概率会延伸到 Google Workspace for Education 所有等级。
- 外部视频接入仍是长期短板。Google 不会亲自去抓 B 站、抖音的字幕,这块生态位继续留给第三方工具。
- 教学用 AI 会分化出两层:机构共享型(NotebookLM 走这条)和个人生产型(BibiGPT、Obsidian + AI 插件走这条),两层之间通过文件/笔记标准协议打通。
六、FAQ
Q1:普通教师(不买 Education Plus)能用上 NotebookLM Classroom 集成吗?
当前不能。Google 明确只面向 Education Plus 和 Teaching and Learning 附加版,免费版 Classroom 教师需要等待下一轮扩展。
Q2:B 站视频能直接丢给 NotebookLM 吗?
不能。NotebookLM 目前只支持 YouTube 链接、PDF、Google Docs 等官方生态内的 Source。B 站、抖音、小红书、播客等外部视频需要先用 BibiGPT 等第三方工具转成文本或 PDF 再导入。
Q3:BibiGPT 的合集 AI 对话和 NotebookLM 相比,主要差异在哪?
合集 AI 对话处理的是外部异构视频来源(B 站、YouTube、小红书、播客、本地文件混合),NotebookLM 处理的是机构内结构化资料。一个覆盖公开网络,一个覆盖校内知识产权。
Q4:我已经是 Education Plus 机构老师,今天就能用吗?
不一定。Google 的分阶段推送通常在域内以批次 rollout,部分账号可能要等到 2026-05 才看到 Classroom Source 选项。可以先让 IT 管理员检查 NotebookLM 功能开关。
Q5:教师端用 BibiGPT 做备课,数据安全怎么处理?
BibiGPT 提供企业/教育版支持私有空间、链接私有、云同步选项可控。敏感课堂录播建议用私有链接模式处理,再把结构化结果导出到 Classroom。
Q6:是否支持中文课堂场景?
支持。BibiGPT 原生覆盖中文音视频(含方言识别),而 NotebookLM 的 Classroom 集成同样支持中文界面。两者结合特别适合中国的国际学校和双语项目。
立即试用:给你的 Classroom 补上外部视频入口
想体验一下"把 B 站课程喂给 NotebookLM"的工作流?
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
或者直接看成品:把一节 B 站公开课丢进 BibiGPT 会变成什么样?
See BibiGPT's AI Summary in Action
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Free更多深度对比可以看这两篇前作:
想看核心功能?试试 BibiGPT 合集 AI 对话、自定义提示词总结、Obsidian 自动保存。
BibiGPT 团队