NotebookLM 2026 四月更新全解读:三栏布局 + 10 款信息图 + Flashcards 跨会话,对比 BibiGPT 谁更适合中文视频
NotebookLM 2026 年 4 月推出三栏布局、10 款信息图模板、跨会话 Flashcards。本文实测并对比 BibiGPT 在中文视频源(B站/小红书)和中文语境的差异化优势。
NotebookLM 2026 四月更新全解读:三栏布局 + 10 款信息图 + Flashcards 跨会话,对比 BibiGPT 谁更适合中文视频
一句话回答: NotebookLM 在 2026 年 4 月迎来了它今年最大的一次更新——三栏工作区布局、10 款全新信息图(Infographic)模板、Flashcards 跨会话持久化。对英文学习者和论文研究者来说这是质的飞跃,但对中文 B 站 / 小红书 / 播客用户来说,源内容覆盖依然是硬伤,这正是 BibiGPT 补位的地方。
最近被问得最多的问题之一:「NotebookLM 这次四月更新后是不是已经够用了?」我的答案是:看你喂进去的源是什么。如果是英文 PDF、学术论文、英文 YouTube,NotebookLM 今年四月这波更新的体验确实非常强;但如果是 B 站的课程合集、小红书的干货笔记、中文播客,源头的接入和中文语境的理解依然是短板。这篇文章拆解 4 月更新的三个新能力,再对比 BibiGPT 的差异化优势。
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
2026 年 4 月 NotebookLM 三大更新实测
更新 1:三栏工作区布局——终于不用来回切 Tab 了
NotebookLM 原来是左侧 Sources + 右侧 Chat 的两栏布局,工作流其实挺割裂——你想一边翻源资料一边做笔记,就得在不同面板之间反复跳。四月更新后引入第三栏「Studio」面板,把 FAQ、Timeline、Audio Overview、Infographic、Flashcards、Briefing Doc 等生成产物统一放在这里。三栏分工:Sources(材料) + Chat(对话) + Studio(成品),信息结构终于清晰了。
这个改动本身不算革命,但它释放了一个信号:Google 认为 NotebookLM 的产出物(Infographic、Flashcards 等)和对话结果同等重要,而不只是附属。
更新 2:10 款 Infographic 模板——一图胜千言的官方版
这是四月更新里最出圈的功能。NotebookLM 把 Studio 里的 Infographic 能力从原来的"一个默认样式"扩展到 10 款模板:时间轴型、对比表型、流程图型、层级结构型、地图型、统计图型、故事板型、金字塔型、矩阵型、关系图型。每种模板的排版逻辑都针对某一类信息形态优化,生成质量比原来强一大截。
对研究者、老师、知识博主来说,这是真正实用的升级——原来要用 Mermaid 手画的结构图,现在粘点源材料就出来。
更新 3:Flashcards 跨会话持久化——终于能"长期复习"了
原来 NotebookLM 的 Flashcards 是会话级别的,关了窗口再开就没了,完全没法做间隔复习。四月更新把 Flashcards 改成 Notebook 级别持久化,你可以在几天、几周之后回到这个 Notebook 继续复习,甚至跨多个 Notebook 聚合 Flashcards。
这让 NotebookLM 从"一次性问答工具"向"长期学习伴侣"迈出关键一步。
NotebookLM vs BibiGPT:源内容覆盖是决定性差异
NotebookLM 这波更新主要改的是后端产出形态——Infographic、Flashcards、三栏布局。但它的前端输入依然卡在几类特定格式:
| 输入源 | NotebookLM | BibiGPT |
|---|---|---|
| 英文 PDF / Google Doc | ✅ 原生 | ✅ 支持 |
| YouTube 视频链接 | ✅(英文最强) | ✅(同样强) |
| B 站视频链接 | ❌ 不支持 | ✅ 原生,含三重字幕来源 |
| 小红书笔记/视频 | ❌ 不支持 | ✅ 专项支持 |
| 抖音 / TikTok | ❌ 不支持 | ✅ 专项支持 |
| 中文播客(小宇宙) | ❌ 不支持 | ✅ 原生 |
| 腾讯会议 / 飞书录屏 | ❌ | ✅ 支持上传 |
| 英文网页 URL | ✅ | ✅ |
| 中文网页 URL | ⚠️ 部分 | ✅ |
核心差异: NotebookLM 是为英文学术/研究场景设计的。它的 Audio Overview 播客、Infographic 模板、Flashcards 在英文语境下表现极好。但中文用户的原始素材大头是 B站课程合集、小红书长图文、中文播客——这些 NotebookLM 吃不进去。
延伸阅读:NotebookLM 2026 功能对比 BibiGPT | Gemini Notebooks vs NotebookLM 2026 | NotebookLM Gemini App Integration vs BibiGPT 2026
BibiGPT 的中文视频专属价值
对中文用户来说,BibiGPT 的差异化主要体现在三个地方:
1. 源头接入:一键粘贴 B 站链接
粘贴任意 B 站、小红书、抖音链接,BibiGPT 会自动提取字幕(三重来源:官方字幕 + AI 转录 + 硬字幕识别)。对于那些"UP 主没传官方字幕但画面里烧录了字幕"的视频,硬字幕识别这条路径成功率超过 98%,这是 NotebookLM 完全没有的能力。
2. 中文语境理解:AI 对话不会"翻译腔"
BibiGPT 的 AI 对话追问功能基于国内模型生态优化,提问时不会出现 NotebookLM 那种"把英文翻译成中文"的生硬语气。你问"这一段说的逻辑到底靠不靠谱?",它会用中文读者熟悉的批判性思维方式回应,而不是给你一段书面化的答复。
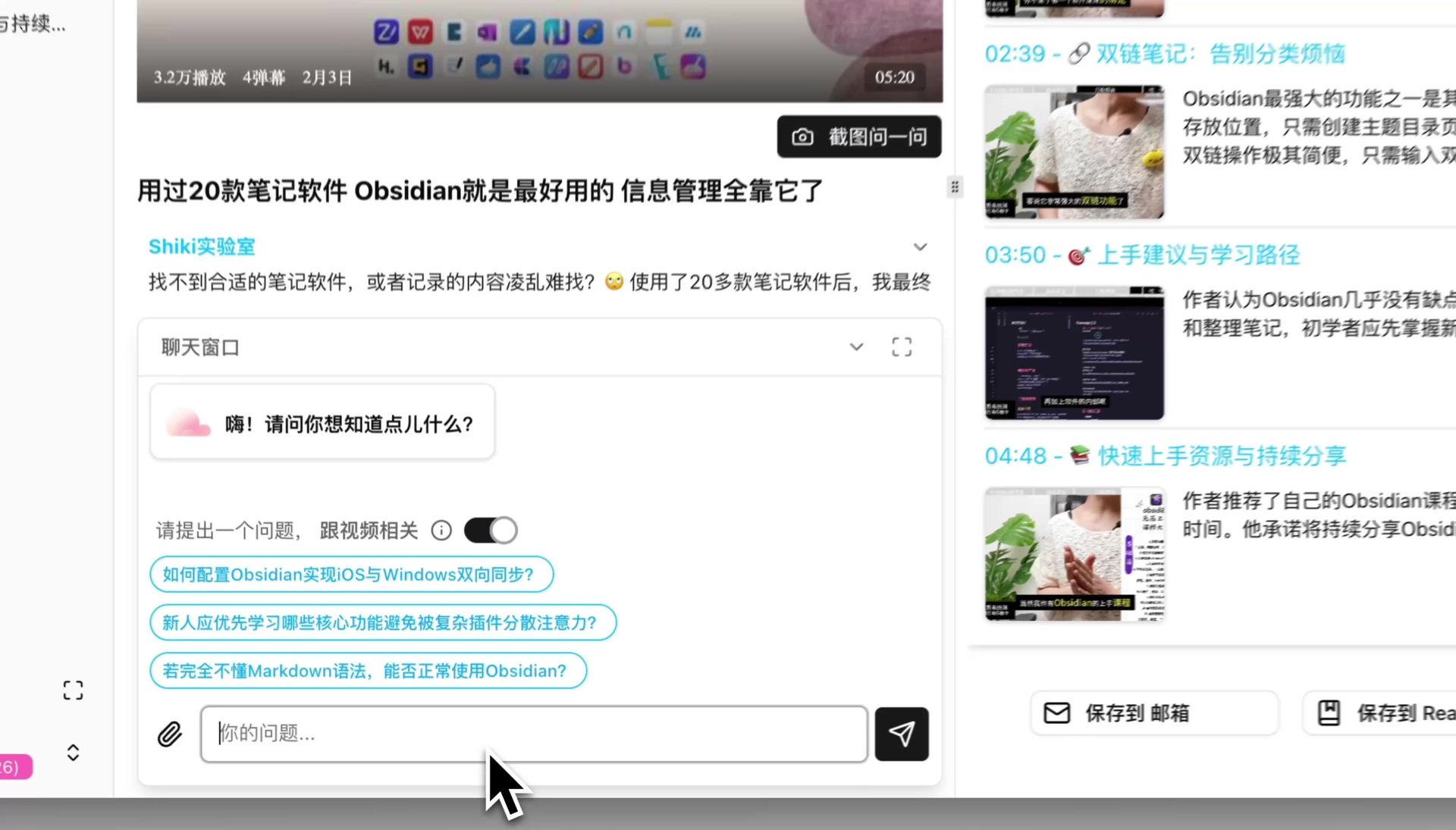 AI 对话窗口输入问题
AI 对话窗口输入问题
3. 多模态产出:PPT 演示 + 思维导图 + 视觉化分析
NotebookLM 四月更新加了 10 款 Infographic,BibiGPT 在这个维度其实走得更远:
- PPT 演示:把视频总结一键生成动态 PPT
- 思维导图:交互式可展开/折叠,每个节点可跳回原视频时间戳
- 视觉化分析:分析视频画面生成公众号图文、小红书卡片、短视频脚本
- AI 视频转文章:把视频一键转成带智能截图的结构化文章
场景选型建议
不是替代关系,而是根据源类型选择工具:
- 英文学术论文、英文 YouTube 深度研究 → NotebookLM 四月更新后体验最好,Infographic + Flashcards + 三栏布局组合拳很强
- 中文 B 站课程合集、小红书长图文、中文播客 → BibiGPT 是现在唯一的完整解
- 研究报告需要多源整合 + 长期复习 → NotebookLM + BibiGPT 并用,各管各的源类型
- 内容创作者需要把视频转 PPT / 图文 / 短视频 → BibiGPT 多模态联动更顺
常见问题(FAQ)
Q1:NotebookLM 四月更新后支持中文视频链接了吗?
A: 没有。Infographic 和 Flashcards 是产出形态的升级,但 Sources 端依然只接受英文为主的 PDF、Google Doc、YouTube、网页 URL。中文视频平台(B 站 / 小红书 / 抖音)仍未支持。
Q2:BibiGPT 也能做 Infographic 吗?
A: 功能等价的是 BibiGPT 的视觉化分析——分析视频画面内容生成公众号图文、小红书图、短视频脚本等。和 NotebookLM 的 Infographic 定位不同:NotebookLM 的 Infographic 更偏"知识结构示意图",BibiGPT 的视觉化分析更偏"可发布的内容产物"。
Q3:Flashcards 跨会话持久化,BibiGPT 有对应功能吗?
A: BibiGPT 的闪记卡支持导出 Anki CSV,直接导入 Anki 做间隔复习。Anki 是公认的最强间隔复习工具,所以 BibiGPT 选择导出而不是自建,把复习这件事交给专业工具。
Q4:NotebookLM 和 BibiGPT 能不能导入彼此的内容?
A: 可以曲线导入。BibiGPT 生成的文章可以导出 Markdown 再粘到 NotebookLM 作为源;NotebookLM 的 Briefing Doc 同样可以保存后上传到 BibiGPT 继续处理。两个工具的生态是互补而不是封闭的。
Q5:我只关心中文视频学习,值得同时用吗?
A: 如果预算有限只选一个,BibiGPT 在中文场景下覆盖面更广——从视频源、AI 对话、PPT 演示到思维导图一条链路走通。NotebookLM 的价值主要在英文场景。
结语:NotebookLM 是英文世界的里程碑,BibiGPT 是中文语境的完整解
四月更新后,NotebookLM 无疑是全球 AI 笔记产品里产出形态最完善的一家。但对于把 B 站视频课程、中文播客、小红书干货当作主要素材来源的中文用户,BibiGPT 依然是更顺手的工具——源头打通、中文语境理解、多模态产出,100万+ 已服务用户、500万+ 累计总结、30+ 支持平台。两个工具并不互斥,源是什么就用什么。
See BibiGPT's AI Summary in Action
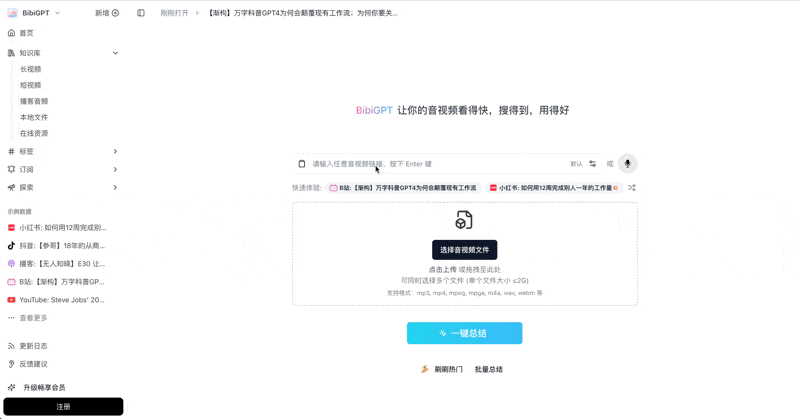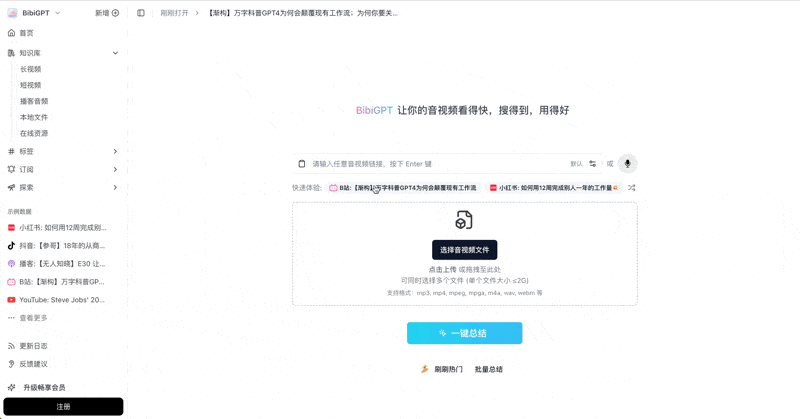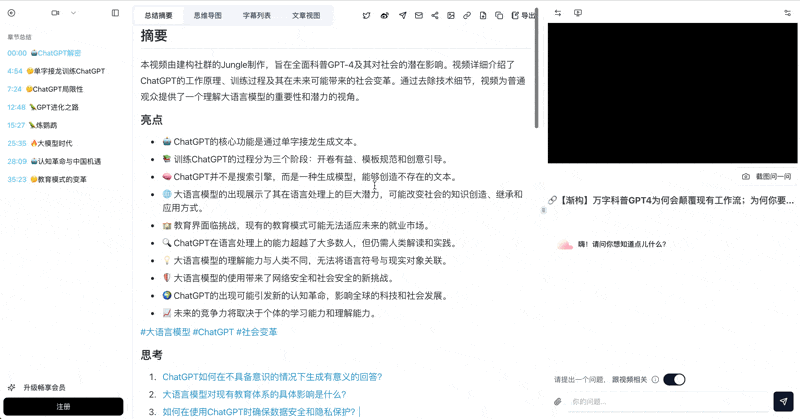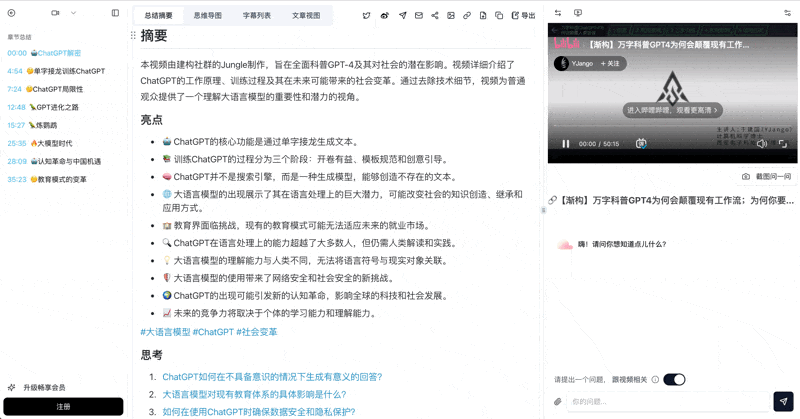
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Free立即访问 BibiGPT 官网,开启你的 AI 高效学习之旅:
- 🌐 官网: https://bibigpt.co
- 📱 移动端下载: https://bibigpt.co/app
- 💻 桌面端下载: https://bibigpt.co/download/desktop
- ✨ 了解更多功能: https://bibigpt.co/features
BibiGPT 团队