マイクロソフト自社音声基盤が来た: MAI-Voice-1 + MAI-Transcribe-1とBibiGPTポッドキャスト要約の新機会
マイクロソフトが2026年4月にMAI-Voice-1(60秒音声を1秒生成)とMAI-Transcribe-1を発表。AIポッドキャスト文字起こし、多言語字幕、動画要約への影響をWhisper / Voxtralと比較し、BibiGPTのカスタム文字起こしエンジン互換ロードマップを解説します。
マイクロソフト自社音声基盤が来た: MAI-Voice-1 + MAI-Transcribe-1とBibiGPTポッドキャスト要約の新機会
目次
- MAI-Transcribe-1とは?AIポッドキャスト文字起こしへの影響は?
- MAI-Voice-1: 60秒音声を1秒で生成
- MAI-Transcribe-1 vs Whisper / Voxtral: 3つの重要な違い
- BibiGPTユーザーへの意味: より頑健な要約土台
- BibiGPTの互換・相補戦略
- よくある質問 (FAQ)
- まとめ
MAI-Transcribe-1とは?AIポッドキャスト文字起こしへの影響は?
結論: MAI-Transcribe-1はマイクロソフトが2026年4月に発表した自社ASR(音声認識)モデルで、MAI-Voice-1(TTS)と同時リリース。AIポッドキャスト文字起こしへの直接的な影響は、多言語・ノイズ環境下でのWER(単語誤り率)のさらなる低下と推論コストの低減。つまりAIポッドキャスト要約のような下流アプリが、より正確な字幕土台をより安く得られるということです。
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
2026年4月2日、マイクロソフトMAI(Microsoft AI)チームは2つの自社音声モデルを同時公開:
- MAI-Voice-1: 音声合成(TTS)。単一GPUで60秒音声を1秒で生成。
- MAI-Transcribe-1: 音声認識(ASR)。多言語ベンチで新SOTA、推論遅延が大幅減。
マイクロソフトが音声スタックの両端を自社モデルに置き換えたのは初(OpenAI Whisperや第三者TTS依存から脱却)。シグナルは明確です — ファウンデーション音声モデルが「自社+エンドツーエンド低遅延」段階に突入し、ポッドキャスト・インタビュー・会議録音の長尺オーディオが最も恩恵を受けるでしょう。
MAI-Voice-1: 60秒音声を1秒で生成
結論: MAI-Voice-1はマイクロソフト自社TTSで、単一GPUで60秒音声を1秒で生成。リアルタイム音声アシスタント、低遅延吹き替え、長文ナレーション等に適し、Copilot Daily / Podcastsに既に統合済み。
ハイライト:
- 60× リアルタイム: 60秒テキスト → 1秒オーディオ(単一GPU)、長尺ナレーションに最適
- 単一GPU稼働: クラスタを要する多数のTTSより導入障壁が低い
- 既に製品内: Copilot Daily News、Podcasts等で使用中
BibiGPTのような「長尺音映像要約 → ポッドキャスト化」ワークフローへの示唆: 入力側のポッドキャスト文字起こしも出力側の「2人対談」生成も低遅延で実行可能に。BibiGPTのポッドキャスト生成は既に動画から2人対談音声を生成可能で、MAI-Voice-1のような高速TTSの成熟で「要約しながらナレーション」がリアルタイムで実現します。
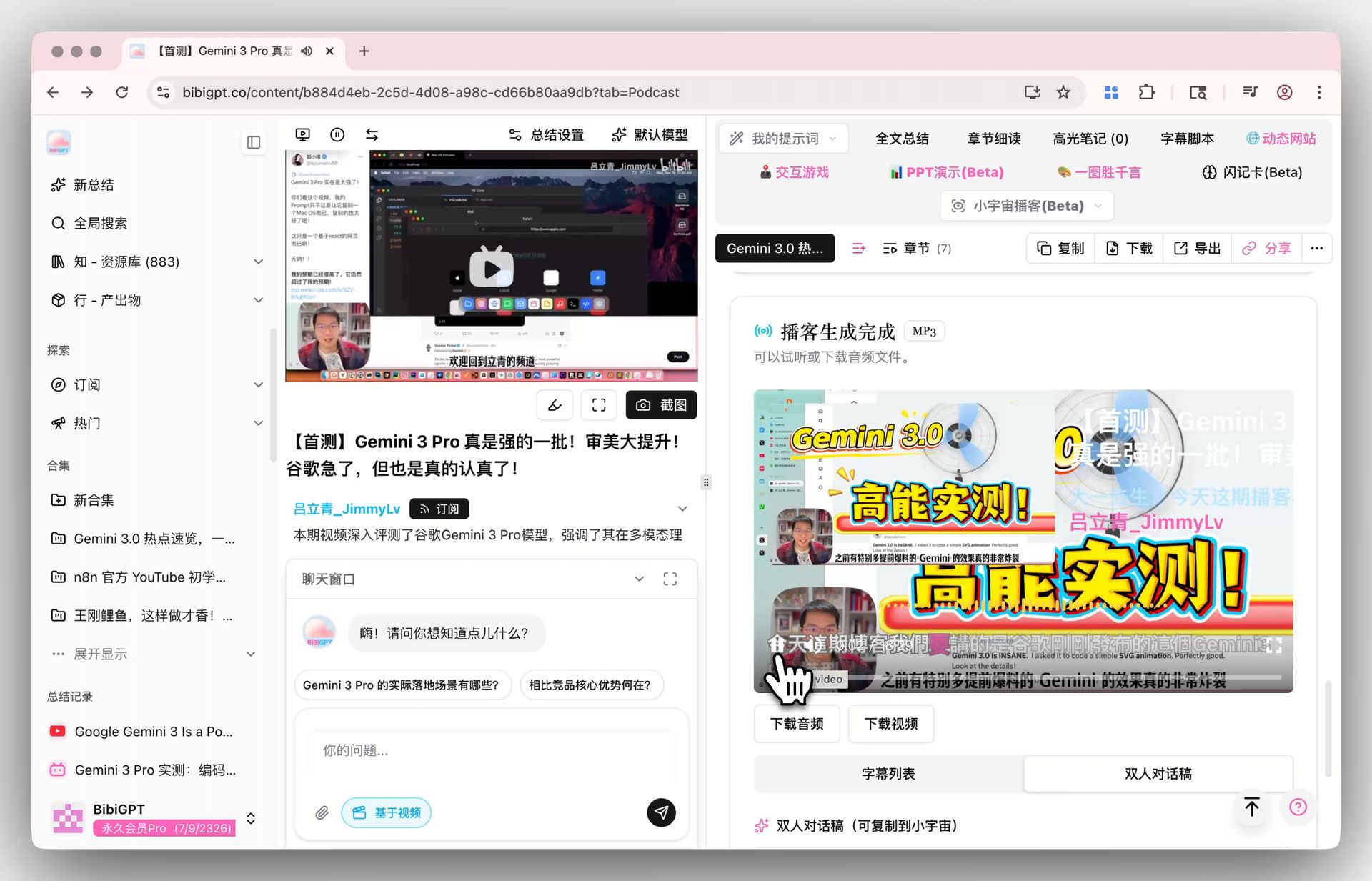 ポッドキャスト生成機能スクリーンショット
ポッドキャスト生成機能スクリーンショット
MAI-Transcribe-1 vs Whisper / Voxtral: 3つの重要な違い
結論: OpenAI Whisper-v3、Mistral VoxtralとMAI-Transcribe-1の主な違いは3点 — より低いWER(ノイズ・専門用語)、より速い推論、Azure / Copilot統合。短期ではWhisperがオープンソースの既定、MAI-Transcribe-1は商用APIの新基準。
| 基準 | MAI-Transcribe-1 | OpenAI Whisper-v3 | Mistral Voxtral |
|---|---|---|---|
| オープンソース | 否(商用API) | 可(MIT) | 可(Apache 2.0) |
| 多言語 | 25+、CJK安定 | 99言語、ロングテール弱め | 英・欧中心 |
| 長尺音声 | ネイティブ60+分 | チャンク必要 | 長コンテキスト |
| 遅延 | Whisper比大幅低 | 中程度 | 速 |
| 配置 | Azureホスティング中心 | ローカル/クラウド | セルフホスト |
| 価格 | 分単位課金 | OSS(GPU自前) | OSS |
Microsoft AI公式ブログによれば、MAIシリーズの目的はマイクロソフトフルスタックAI(Search、Copilot、Office、Gaming、Bing)の音声層を自社技術に統合すること。アプリ層にはより安定したSLAと明確なバージョン管理を意味します。
「単一音声モデル非依存」のBibiGPTにとってMAI-Transcribe-1はカスタム文字起こしエンジンプールのもう一つの選択肢であり、代替ではありません。
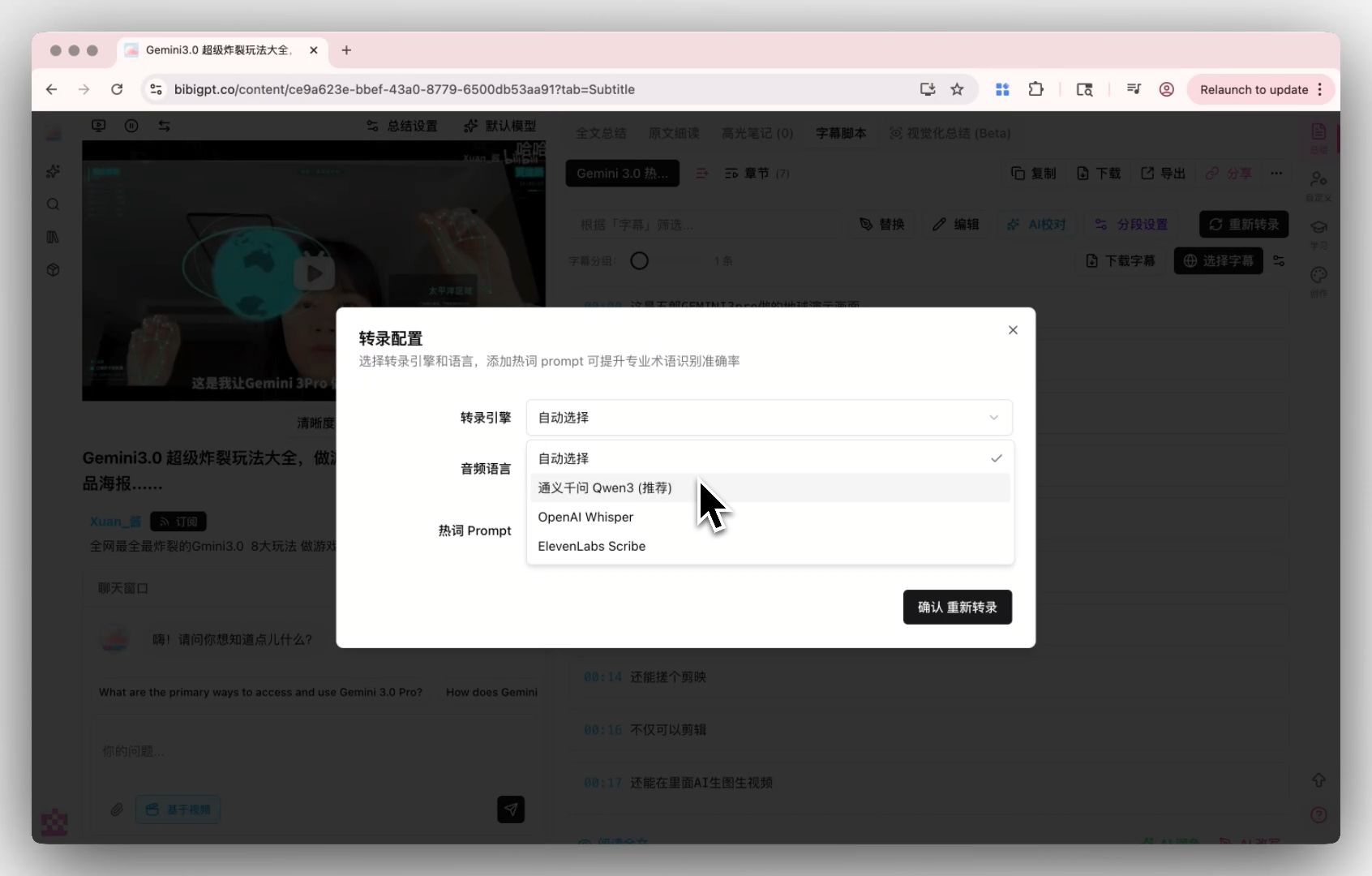 カスタム文字起こしエンジン: プロバイダー選択
カスタム文字起こしエンジン: プロバイダー選択
BibiGPTユーザーへの意味: より頑健な要約土台
結論: BibiGPTユーザーにとってMAI-Transcribe-1発表は3つの実益を意味します — ポッドキャスト・長尺オーディオ文字起こしの精度向上、多言語字幕翻訳ワークフローのスムーズさ、カスタム文字起こしエンジンの選択肢拡大。
ケース1: ポッドキャスト・インタビュー等の長尺オーディオ
30分超の長尺はWhisperの弱点 — チャンクで文脈が途切れる。MAI-Transcribe-1のネイティブ長コンテキストでポッドキャスト・業界インタビューの文字起こし品質がより安定。AIポッドキャスト要約ワークフローガイド参照。
ケース2: 多言語コンテンツの越境整理
地域ニュース、日韓インタビュー、英中混合会議 — MAIシリーズは多言語混在でWERが安定。海外展開・越境リサーチのユーザーにはアップロード時自動翻訳の「認識 → 翻訳」チェーンがより正確なASR土台を得ます。
ケース3: 専門用語密度が高いコンテンツ
医療・法律・金融・技術など用語密集の内容は従来ElevenLabs Scribe等の専門エンジンに依存。MAI-Transcribe-1追加で選択肢が広がり、コンテンツ特性に合う土台を選べます。
BibiGPTの互換・相補戦略
結論: BibiGPTのポジショニングは一度も「単一音声モデル依存」ではなく、「どの強力な土台もユーザー可視の知識成果物にシームレス変換する」こと。MAI-Voice-1 / Transcribe-1登場でBibiGPTの核心フロー(文字起こし → 要約 → マインドマップ → 記事・ポッドキャスト)がより頑健な土台で動きます。
互換パス: MAI-Transcribe-1をカスタム文字起こしエンジンに搭載
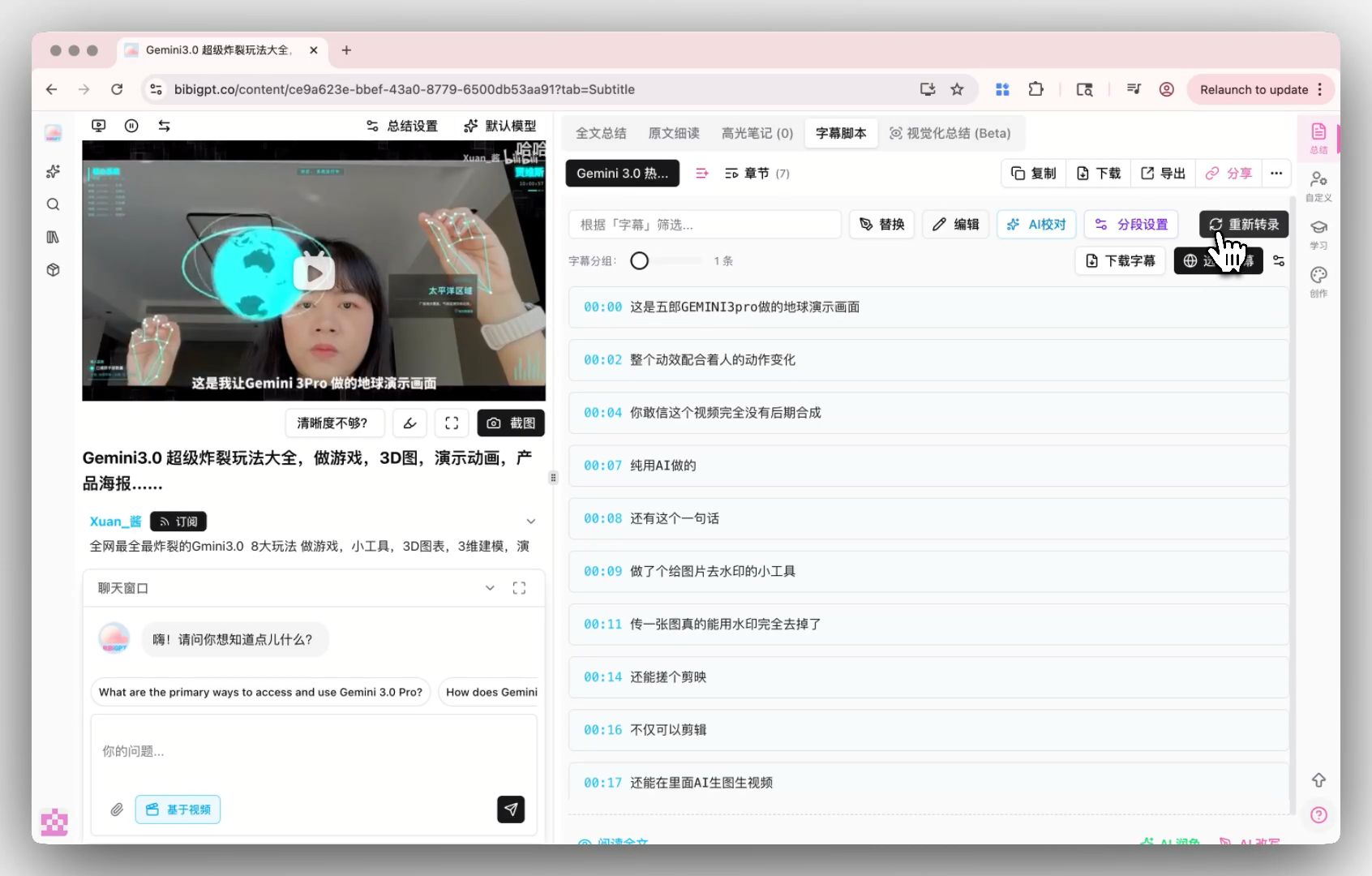 カスタム文字起こしエンジン入口
カスタム文字起こしエンジン入口
BibiGPTのカスタム文字起こしエンジンは現在OpenAI Whisperと業界トップのElevenLabs Scribeをサポート。MAI-Transcribe-1はAzure / Copilot内部利用に留まり、公開API成熟次第プール追加を評価します。
相補パス: MAIは土台、BibiGPTは「知識成果物」加工
最強のASRでもユーザーが受け取るのは純テキストだけ。BibiGPTの独自価値は字幕成果物の次にあります:
- 構造化要約+マインドマップ — 長尺オーディオ知識のチャプター化
- AIハイライトノート — タイムスタンプ付きハイライトをワンクリック
- コレクション要約 — 複数話を横断要約
- 2人ポッドキャスト生成 — 要約を再びポッドキャストに、「ポッドキャスト入力 → ポッドキャスト出力」ループ
「土台は差し替え可、上位プロダクトは安定」というアーキテクチャが、BibiGPTが最新音声技術を継続的に取り込める鍵です。深掘り: Microsoft Copilot vs BibiGPT動画要約、MAI-Transcribe-1 vs Cohereオープンソース ASR。
AI Subtitle Extraction Preview
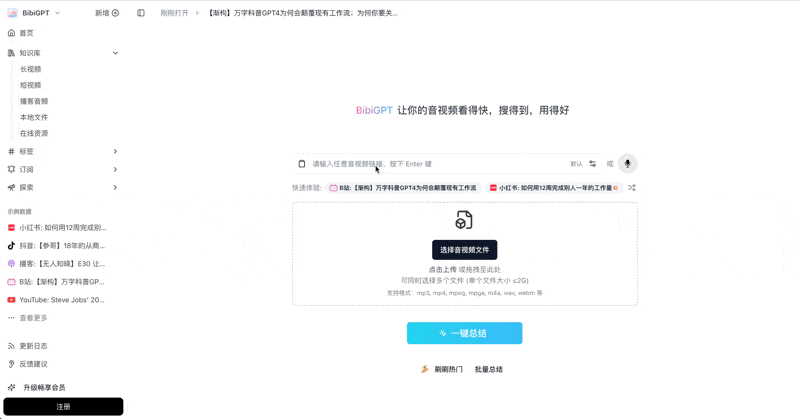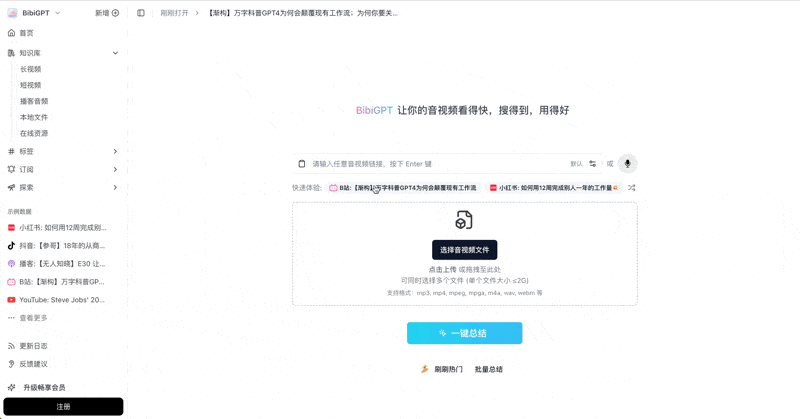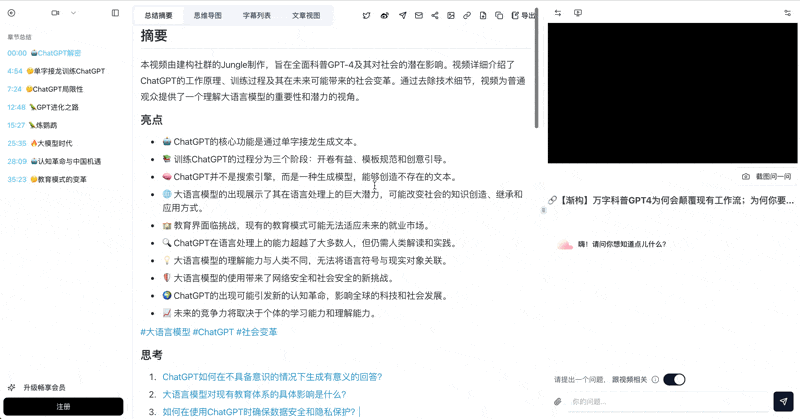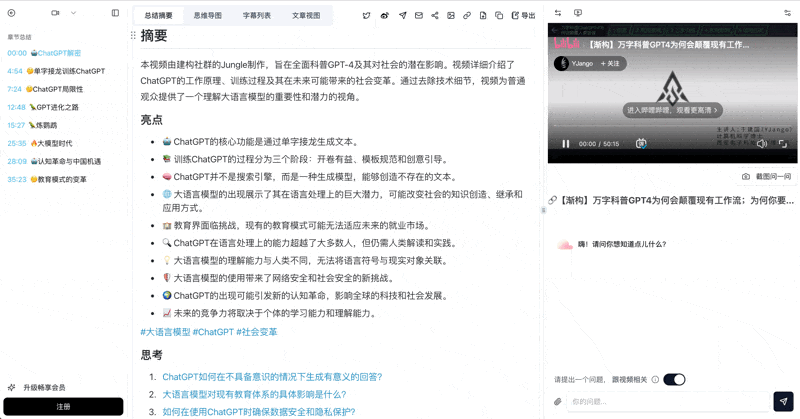
Bilibili: GPT-4ワークフロー革命
GPT-4がどのように仕事を変革するかを深掘りした科学解説動画。モデルの内部構造、学習段階、社会的影響を網羅。
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Freeよくある質問 (FAQ)
Q1: MAI-Transcribe-1はオープンソースですか?セルフホストできますか?
A: いいえ。現在MAI-Transcribe-1は商用提供のみ(Azure / Copilot)。セルフホストが必要ならOpenAI Whisper(MIT)かMistral Voxtral(Apache 2.0)をお使いください。
Q2: BibiGPTはデフォルトでMAI-Transcribe-1を使用していますか?
A: まだです。BibiGPTは自社+Whisperハイブリッドをデフォルトにし、カスタム文字起こしエンジンでElevenLabs Scribeへ切替可能。MAI-Transcribe-1は公開API成熟後に評価予定。
Q3: MAI-Voice-1がポッドキャスト制作者にもたらす直接的メリットは?
A: 制作者は将来MAI-Voice-1のような高速TTSで原稿を複数話者音声に逆変換可能。BibiGPTのポッドキャスト生成は既に動画から2人対談を生成でき、TTSの進歩で遅延がさらに下がります。
Q4: 日本語ポッドキャストでMAI-Transcribe-1はWhisperよりどれだけ優れていますか?
A: 現在日本語の公開ベンチは限定的。BibiGPTでWhisperとElevenLabs Scribeを並行実行して比較し、MAI-Transcribe-1公開後に実測比較を掲載予定。
Q5: なぜすべての文字起こしを最強モデル既定にしないのですか?
A: モデル毎にコスト・精度・言語カバーのトレードオフが異なります。単一モデルハードバインドは希少言語・専門用語等の極端ケースで選択権を失います。BibiGPTのカスタム文字起こしエンジンはこれをユーザーに戻します。
まとめ
マイクロソフトMAI-Voice-1 + MAI-Transcribe-1の発表は、ファウンデーション音声モデルの「自社+エンドツーエンド低遅延」段階入りを示します。AI音映像ツールには土台能力の総合アップグレード — より正確な文字起こし、より速い合成、より頑健な長尺オーディオ。
BibiGPTの製品哲学は一度も特定モデル依存ではなく、どんな強力な土台もユーザー可視の知識成果物にシームレス変換すること。MAI成熟時、BibiGPTは第一時間でカスタム文字起こしエンジンプールに追加し、日本語ポッドキャスト・越境動画・長尺オーディオ学習シナリオに最も安定したAI要約体験を提供し続けます。
今すぐAI効率的な学習の旅を始めましょう:
- 🌐 公式ウェブサイト: https://aitodo.co
- 📱 モバイルダウンロード: https://aitodo.co/app
- 💻 デスクトップダウンロード: https://aitodo.co/download/desktop
- ✨ より多くの機能を学ぶ: https://aitodo.co/features
BibiGPT チーム