Microsoft's Own Voice Stack: What MAI-Voice-1 + MAI-Transcribe-1 Mean for BibiGPT Podcast Summaries
Microsoft unveiled MAI-Voice-1 (60s of audio in 1s) and MAI-Transcribe-1 in 2026. What do these first-party voice models mean for AI podcast transcription and BibiGPT users? A hands-on breakdown and compatibility roadmap.
Microsoft's Own Voice Stack: What MAI-Voice-1 + MAI-Transcribe-1 Mean for BibiGPT Podcast Summaries
Contents
- What Is MAI-Transcribe-1 and Why Does It Matter for AI Podcast Transcription?
- MAI-Voice-1: 60 Seconds of Audio in 1 Second
- MAI-Transcribe-1 vs Whisper / Voxtral: Three Key Differences
- What It Means for BibiGPT Users: A Sturdier Podcast-Summary Base
- How BibiGPT Plans to Coexist With the MAI Series
- FAQ
- Wrap-up
What Is MAI-Transcribe-1 and Why Does It Matter for AI Podcast Transcription?
Quick answer: MAI-Transcribe-1 is Microsoft's first-party ASR (automatic speech recognition) model, announced in April 2026 alongside MAI-Voice-1. Its immediate effect on AI podcast transcription is a lower word error rate (WER) in multilingual and noisy scenarios, with lower inference cost — so downstream tools like AI podcast summarizers can build on more accurate transcripts for less money.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
On April 2, 2026, Microsoft's MAI (Microsoft AI) team shipped two first-party voice models at once:
- MAI-Voice-1 — text-to-speech (TTS). 60 seconds of audio in 1 second on a single GPU.
- MAI-Transcribe-1 — automatic speech recognition (ASR). New SOTA on multilingual benchmarks with notably lower latency.
This is the first time Microsoft has swapped both ends of its voice stack for in-house models instead of relying on OpenAI Whisper or third-party TTS. The signal is clear: foundation voice models are entering a "first-party + low-latency end-to-end" era, and long-form audio (podcasts, interviews, meetings) will benefit the most.
MAI-Voice-1: 60 Seconds of Audio in 1 Second
Quick answer: MAI-Voice-1 is Microsoft's first-party TTS model. Microsoft claims 60 seconds of audio in 1 second on a single GPU — among the fastest TTS models in production. It's already live inside Copilot Daily / Podcasts, with clear implications for real-time assistants, low-latency dubbing and long-form text narration.
Highlights:
- 60× real-time: 60 seconds of text → 1 second of audio output, ideal for long-form narration
- Runs on a single GPU, unlike many TTS systems that need a cluster
- Already in production inside Copilot Daily News and Podcasts workflows
Implication for "long audio-video summary → podcast" scenarios like BibiGPT: both the input side (podcast transcription) and the output side (generating "two-host podcast" audio) can now run with much lower latency. BibiGPT's podcast generation already turns any video into a two-host conversation; as fast TTS like MAI-Voice-1 matures, "summarize while narrating" becomes feasible in real time.
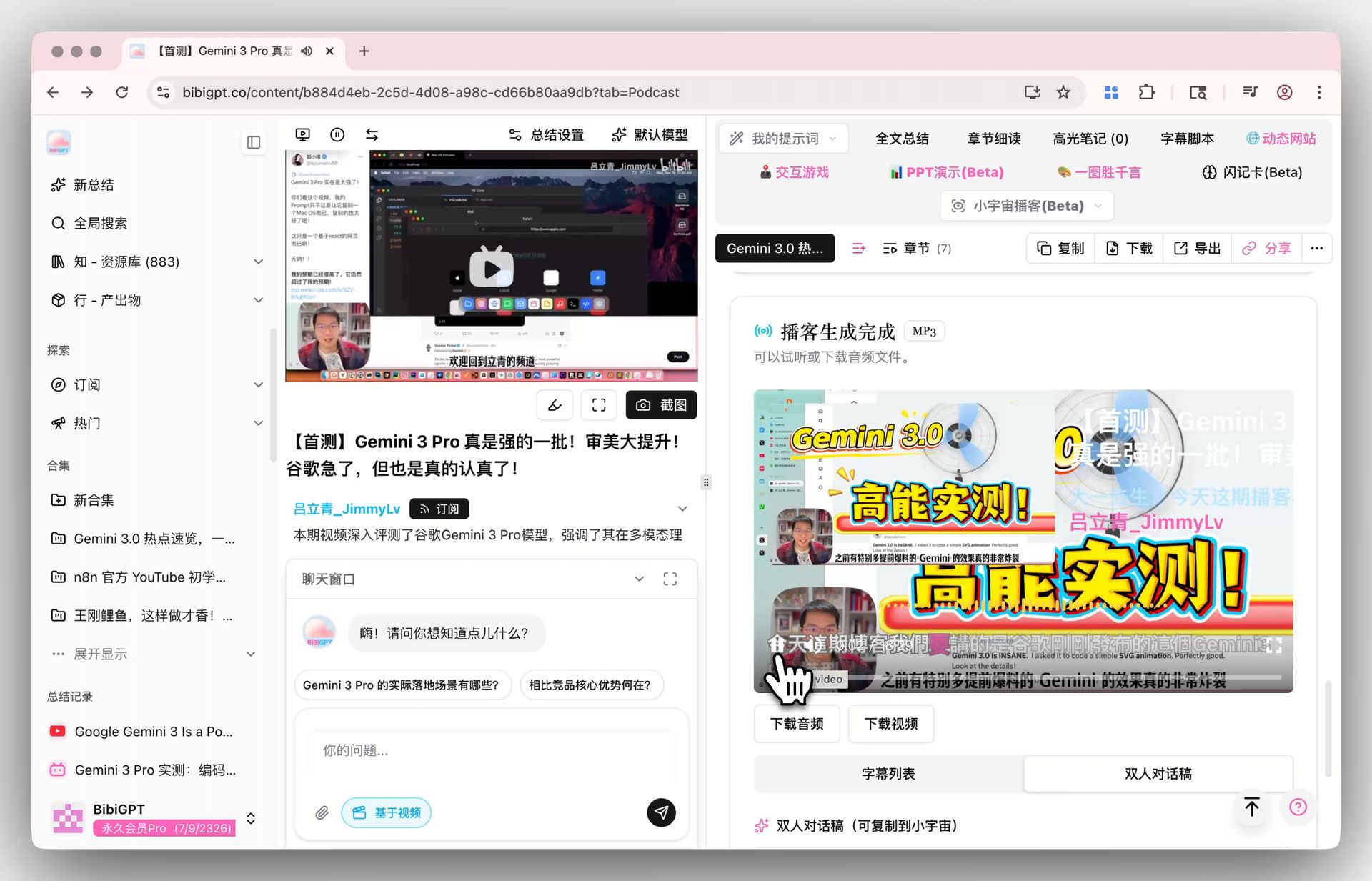 Podcast generation feature screenshot
Podcast generation feature screenshot
MAI-Transcribe-1 vs Whisper / Voxtral: Three Key Differences
Quick answer: Compared to OpenAI Whisper-v3 and Mistral Voxtral, MAI-Transcribe-1 stands out on three axes: lower WER (especially in noisy environments and on domain terms), faster inference, and tight Azure / Copilot integration. Short-term, Whisper is still the open-source default; MAI-Transcribe-1 becomes the new commercial API benchmark.
| Dimension | MAI-Transcribe-1 | OpenAI Whisper-v3 | Mistral Voxtral |
|---|---|---|---|
| Open source | No (commercial API) | Yes (MIT) | Yes (Apache 2.0) |
| Multilingual | 25+ languages, stable CJK | 99 languages, weaker on long-tail | EN + EU-centric |
| Long audio | Native 60+ min context | Needs chunking | Long context supported |
| Latency | Significantly lower than Whisper | Medium | Fast |
| Deployment | Azure-hosted | Self-host or cloud | Self-host open source |
| Pricing | Per-minute | Open source (pay for GPU) | Open source |
Per Microsoft AI's blog, the MAI series is meant to consolidate the voice stack across Microsoft's full-stack AI (Search, Copilot, Office, Gaming, Bing) on first-party tech. For downstream apps, that translates to more stable SLAs and clearer model versioning.
For a product like BibiGPT — which doesn't marry any single voice model — MAI-Transcribe-1 is one more option in the custom transcription engine pool, not a replacement.
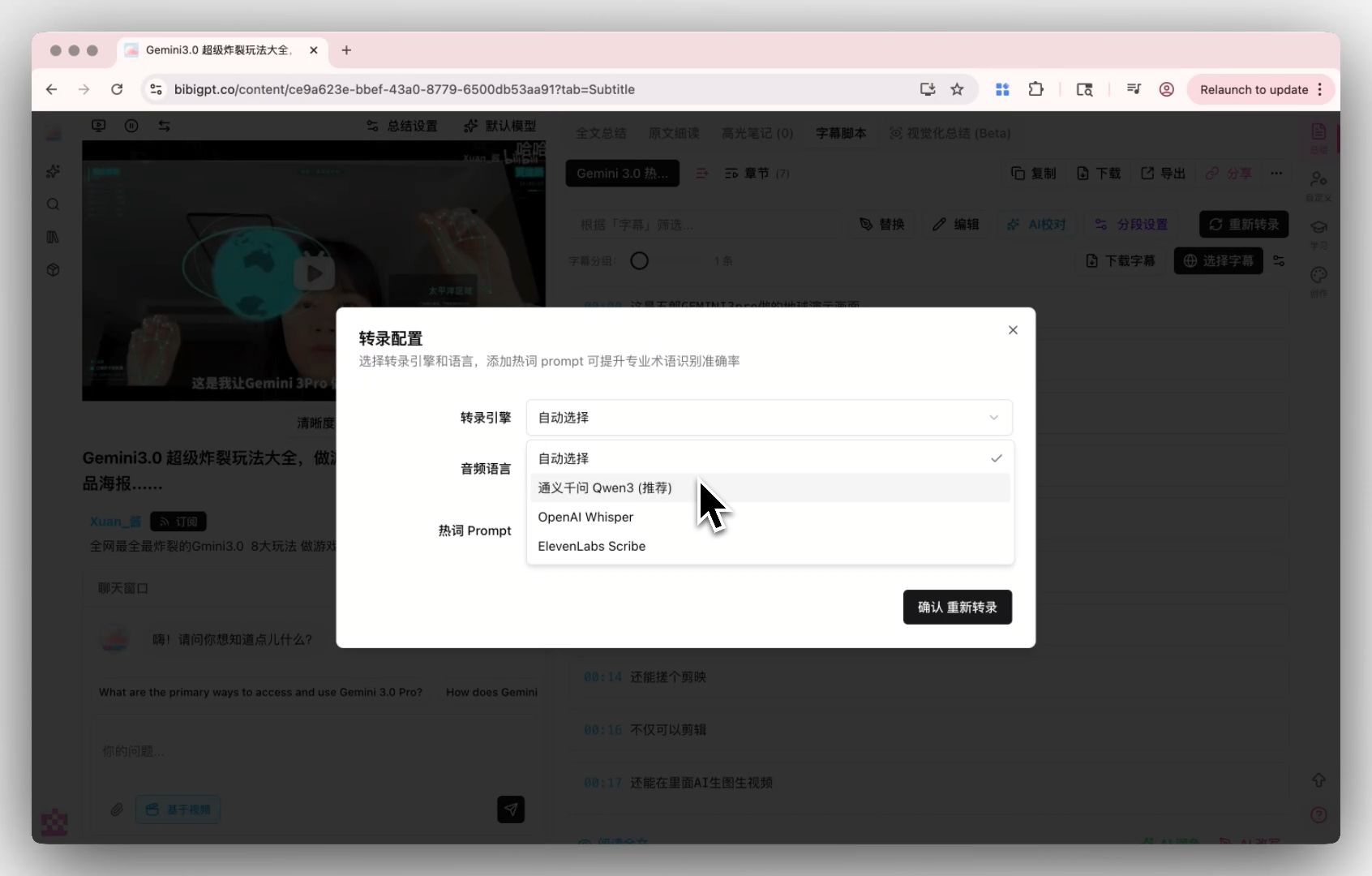 Custom transcription engine — provider selection
Custom transcription engine — provider selection
What It Means for BibiGPT Users: A Sturdier Podcast-Summary Base
Quick answer: Three concrete wins for BibiGPT users — more accurate transcription for podcasts and long audio, smoother multilingual subtitle translation workflow, and a richer pool of custom transcription engines to choose from.
Case 1: Long-form podcast / interview audio
Long audio (>30 min) is Whisper's weak spot — chunking loses context. MAI-Transcribe-1's native long-context support means Spotify podcasts and industry interviews transcribe more cleanly. See the AI podcast summary workflow guide for comparisons.
Case 2: Cross-border multilingual content
News across regions, JP / KR interviews, EN-CN bilingual meetings — MAI's multilingual WER is more stable in mixed scenarios. For creators going global or cross-border researchers, the auto-translate on upload chain (recognize → translate) gets a more accurate ASR base.
Case 3: Term-dense domain content
Medical, legal, financial, technical — dense terminology has long leaned on specialist engines like ElevenLabs Scribe. Adding MAI-Transcribe-1 broadens the pool, so users can pick whichever balance of price / accuracy / language fits their content best.
How BibiGPT Plans to Coexist With the MAI Series
Quick answer: BibiGPT's positioning has never been to bet on a single voice model. MAI-Voice-1 / Transcribe-1 make BibiGPT's core flow (transcribe → summarize → mind map → article / podcast) run on a sturdier base.
Compatibility path: plug MAI-Transcribe-1 into the custom transcription engine
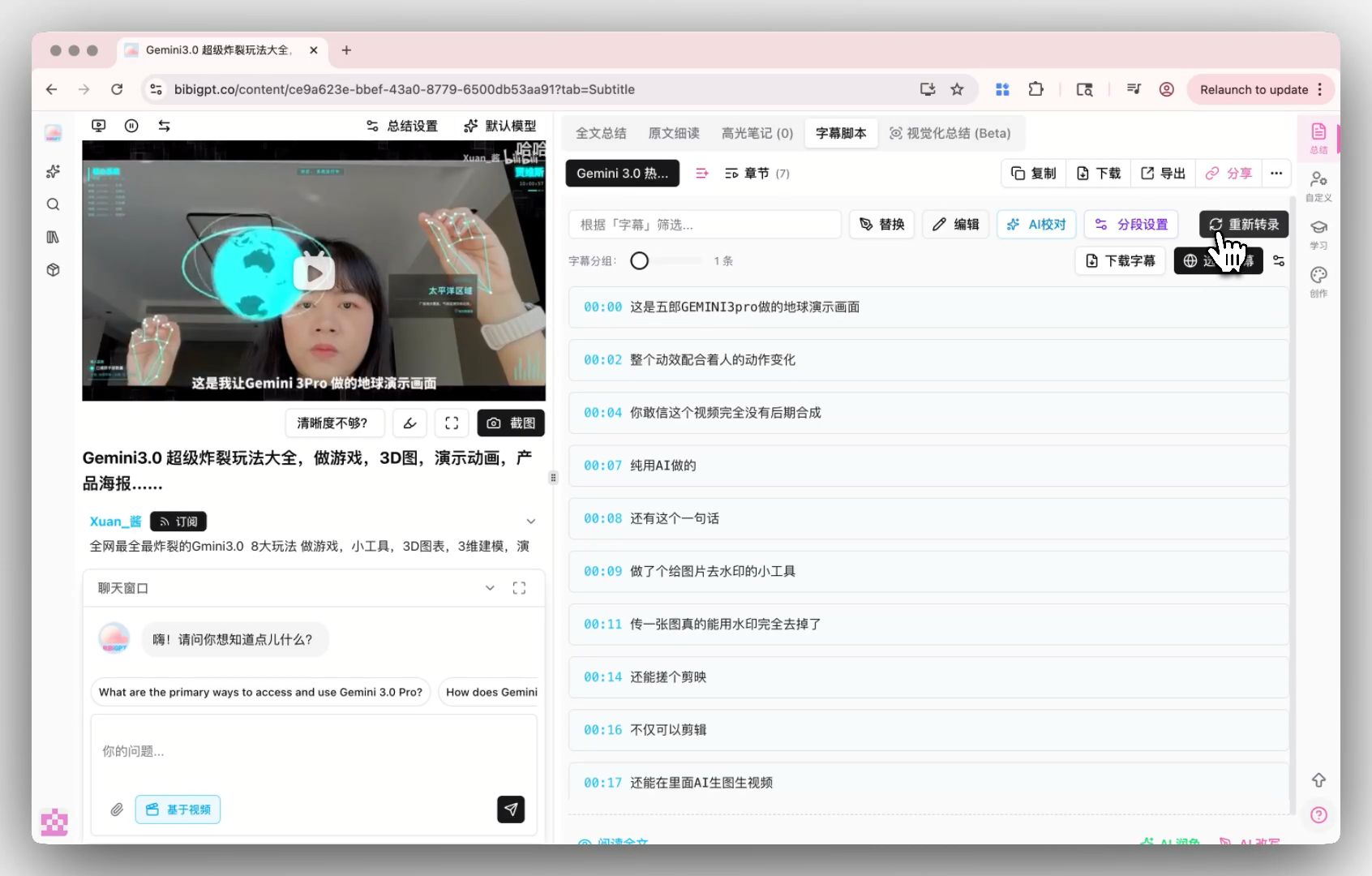 Custom transcription engine entry
Custom transcription engine entry
BibiGPT's custom transcription engine today supports OpenAI Whisper and the industry-leading ElevenLabs Scribe. MAI-Transcribe-1 is currently Azure / Copilot-only; once public APIs mature, BibiGPT will evaluate adding it to the pool so users can switch engines right from the subtitle editor.
Complement path: MAI as base, BibiGPT as knowledge-artifact layer
Even with the best ASR, the raw output is still just text. BibiGPT's unique value sits downstream of the transcript:
- Structured summaries + mind maps — chapter-level breakdown of long audio
- AI highlight notes — time-stamped highlights with one click
- Collection summary — multi-episode synthesis into a knowledge map
- Two-host podcast generation — summary turned back into audio, closing the "podcast → podcast" loop
This "swap-the-base, keep-the-product-layer" architecture is what lets BibiGPT absorb the best voice models as they appear. Deeper reading: Microsoft Copilot vs BibiGPT video summary and the earlier take on MAI-Transcribe-1 vs Cohere open-source ASR.
AI Subtitle Extraction Preview
Bilibili: GPT-4 & Workflow Revolution
A deep-dive explainer on how GPT-4 transforms work, covering model internals, training stages, and the societal shift ahead.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeFAQ
Q1: Is MAI-Transcribe-1 open source? Can I self-host?
A: No. MAI-Transcribe-1 is currently a commercial offering through Azure / Copilot. For self-hosting, stick with OpenAI Whisper (MIT) or Mistral Voxtral (Apache 2.0).
Q2: Does BibiGPT use MAI-Transcribe-1 by default?
A: Not yet. BibiGPT today uses an in-house + Whisper hybrid pipeline; users can switch to ElevenLabs Scribe in the custom transcription engine. MAI-Transcribe-1 will be evaluated once public APIs mature.
Q3: What does MAI-Voice-1 mean for podcast creators?
A: Creators will eventually be able to use fast TTS like MAI-Voice-1 to reverse a transcript into multi-host audio. BibiGPT's podcast generation already turns a video into a two-host conversation; faster TTS will drop latency further.
Q4: How much better is MAI-Transcribe-1 than Whisper on Chinese podcasts?
A: Public benchmarks for Chinese are limited. Use BibiGPT to run Whisper vs ElevenLabs Scribe side-by-side today; once MAI-Transcribe-1 opens up, BibiGPT will publish a hands-on comparison.
Q5: Why not default everyone to the strongest model?
A: Different models trade off cost, accuracy and language coverage. Hard-binding a single model would strip users of control in edge cases (rare languages, domain terms). The custom transcription engine puts that choice back in the user's hands.
Wrap-up
Microsoft's MAI-Voice-1 + MAI-Transcribe-1 mark a new phase for foundation voice models: first-party and end-to-end low latency. For AI audio-video tools, that's a whole-stack upgrade — more accurate transcription, faster synthesis, sturdier long audio.
BibiGPT's product philosophy has never been to lock in one voice model — it's to turn any strong base into user-facing knowledge artifacts. When MAI matures, BibiGPT will add it to the custom transcription engine pool and keep delivering the most reliable AI summaries for podcasts, cross-border videos and long-form learning.
Start your AI efficient learning journey now:
- 🌐 Official Website: https://aitodo.co
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Learn More Features: https://aitodo.co/features
BibiGPT Team