AI 好记 vs BibiGPT:2026 AI 会议笔记工具深度横评(职场人选型指南)
AI 好记专注会议录音转写,BibiGPT 覆盖从会议到 B 站/YouTube/播客的全场景 AI 总结。本文从功能、价格、适用场景三维度深度对比,帮职场人选对工具。
AI 好记 vs BibiGPT:2026 AI 会议笔记工具深度横评(职场人选型指南)
80 字直答:AI 好记是专精会议场景的录音转写 + 笔记工具,适合职场内会议高频用户;BibiGPT 是覆盖更广的 AI 音视频助理,既能处理会议录音也能处理 B 站 / YouTube / 播客等外部视频,并支持 AI 对话追问、合集知识库、Obsidian 自动同步。只开会选 AI 好记,同时需要消费外部视频内容选 BibiGPT。
这是一篇写给需要在会议、线上学习、内容研究之间切换的职场人的选型文章。不吹任何一方,对比到具体场景。
一、两款产品定位对比
| 维度 | AI 好记 | BibiGPT |
|---|---|---|
| 核心定位 | 会议录音转写 + 笔记 | AI 音视频助理(全场景) |
| 输入来源 | 会议录音、本地音频 | 粘贴链接(B 站/YouTube/小宇宙/抖音/TikTok/小红书)+ 本地文件 + 会议录音 |
| AI 总结 | 会议纪要结构(议题、决议、待办) | 章节时间戳 + 自由结构 + 自定义提示词 |
| AI 对话追问 | 针对当次会议 | 单视频追问 + 跨合集追问 |
| 多语言输出 | 主要中文 | 中 / 英 / 日 / 韩 / 繁体 |
| 笔记同步 | 站内为主 | Obsidian 自动保存 / Notion / 飞书 / 语雀 |
| 桌面客户端 | 有 | 有(Tauri 多平台) |
| 移动端 | 有 | 有(Expo) |
| 浏览器插件 | 部分 | 有(Chrome / Firefox / Edge) |
二、场景化对比:五个真实使用场景
场景 1:公司内部周会 / 项目会
AI 好记:主场。会议纪要按"议题—讨论—决议—待办"结构输出,对齐 OKR / 项目管理的习惯。录音直接上传即可。
BibiGPT:也能做,会议录音支持上传 + 转写 + AI 总结。但默认总结结构更接近视频章节(非"决议/待办"格式),需要用自定义提示词切换为会议纪要风格。
选谁:频繁开会 + 只关心会议纪要 → AI 好记。会议 + 视频学习并重 → BibiGPT。
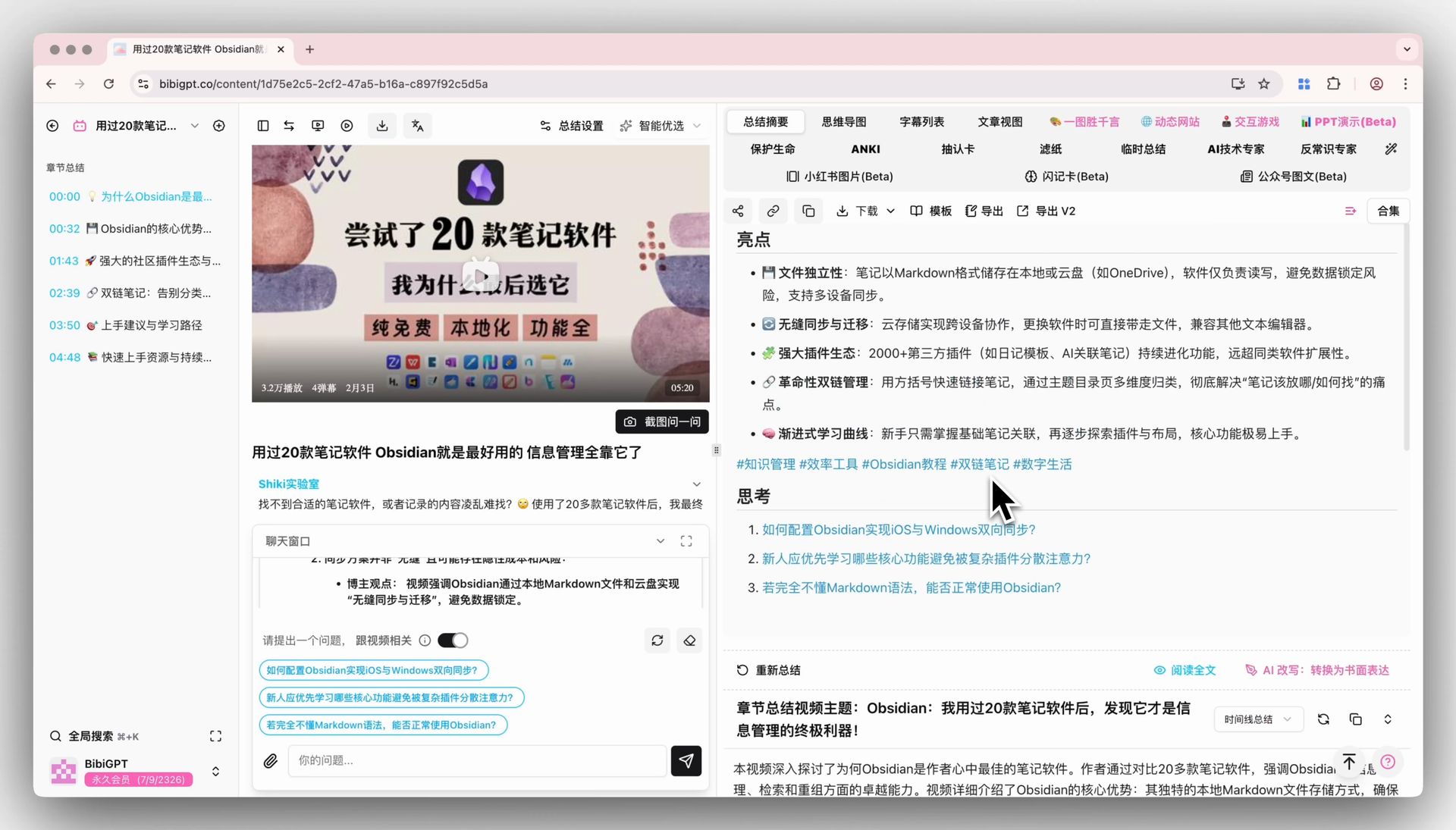
场景 2:线上课程 / B 站 / YouTube 学习笔记
AI 好记:不是主场。需要先把视频录音下载再上传,流程绕。
BibiGPT:一键粘贴 B 站 / YouTube 链接,10 秒出章节时间戳 + AI 总结 + 字幕,支持跳转播放。
 自定义提示词总结
自定义提示词总结
选谁:线上学习场景 → BibiGPT 完胜。
场景 3:播客深度消化(小宇宙 / Apple Podcasts)
AI 好记:需要手动下载音频后上传。
BibiGPT:支持直接粘贴小宇宙链接,自带转写 + AI 总结 + 章节跳转。
选谁:播客用户 → BibiGPT。
场景 4:跨语言会议(外企 / 跨境团队)
AI 好记:主要面向中文市场,英文/多语言支持较弱。
BibiGPT:原生支持中英日韩等多语言总结与翻译,英文视频可直接输出中文总结,适合外企、跨境电商、国际学校。
选谁:涉外会议 / 跨语言 → BibiGPT。
场景 5:构建长期知识库
AI 好记:会议纪要集中管理在站内,导出笔记需要手动。
BibiGPT:自动保存到 Obsidian Vault,合集跨视频 AI 对话,形成个人知识网络。
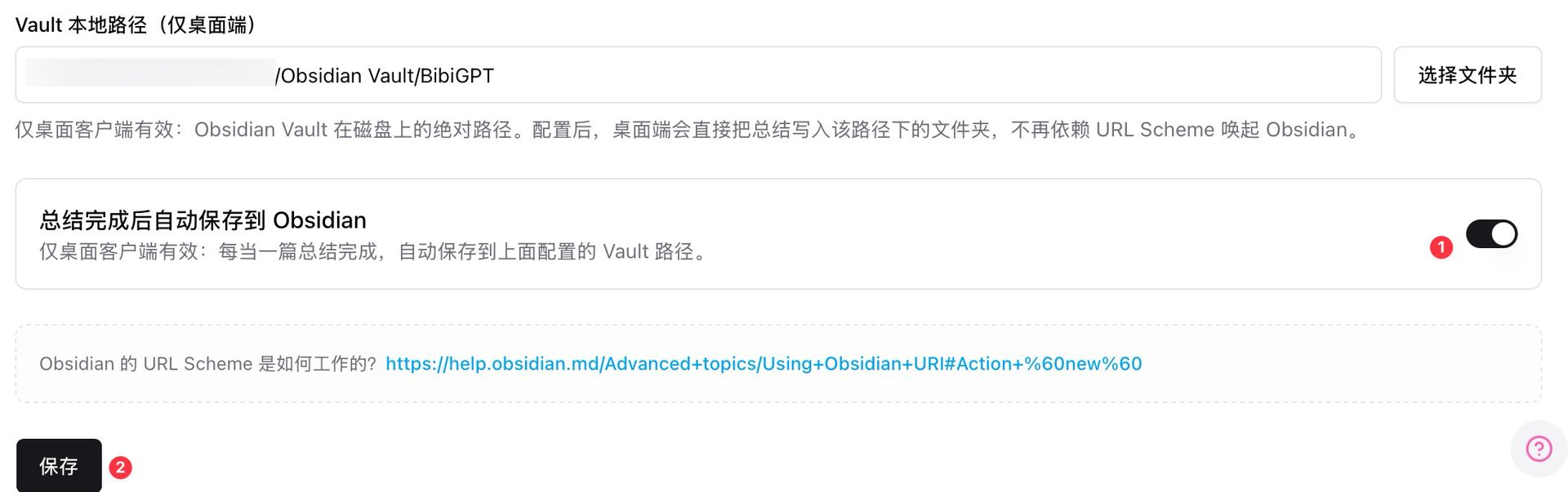 Obsidian 自动保存
Obsidian 自动保存
选谁:重度 PKM 使用者 → BibiGPT。
三、价格与订阅
两款产品都采用免费额度 + 订阅的模式。AI 好记偏向按会议时长计费的模式,适合高频会议用户订阅。BibiGPT有 Plus / Pro 订阅和按需充值(适合 API 客户),详细权益见 bibigpt.co/pricing。
注:两者具体定价会随时调整,以官网实时价格为准。
四、对"混合场景"职场人的真实建议
如果你每周的内容消费是这样:
- 2-3 场内部会议
- 2-3 篇 B 站 / YouTube 干货视频
- 1-2 档小宇宙播客
- 偶尔看英文访谈 / 发布会
那么单独用 AI 好记会留下 B 站 / YouTube / 播客的盲区,你要么另外用一个工具补,要么手动做笔记。这时 BibiGPT 的"一个工具打全场"价值最大。
反过来,如果你只开会不看视频(比如全职项目经理 / HR),AI 好记的会议纪要模板更贴合你已有的会议纪要风格习惯,不需要多学工具。
五、BibiGPT 的差异化能力(AI 好记暂无或弱)
1. 合集 AI 对话:跨视频知识库
把多个同主题视频放进合集,一次提问,AI 整合所有视频的知识回答。
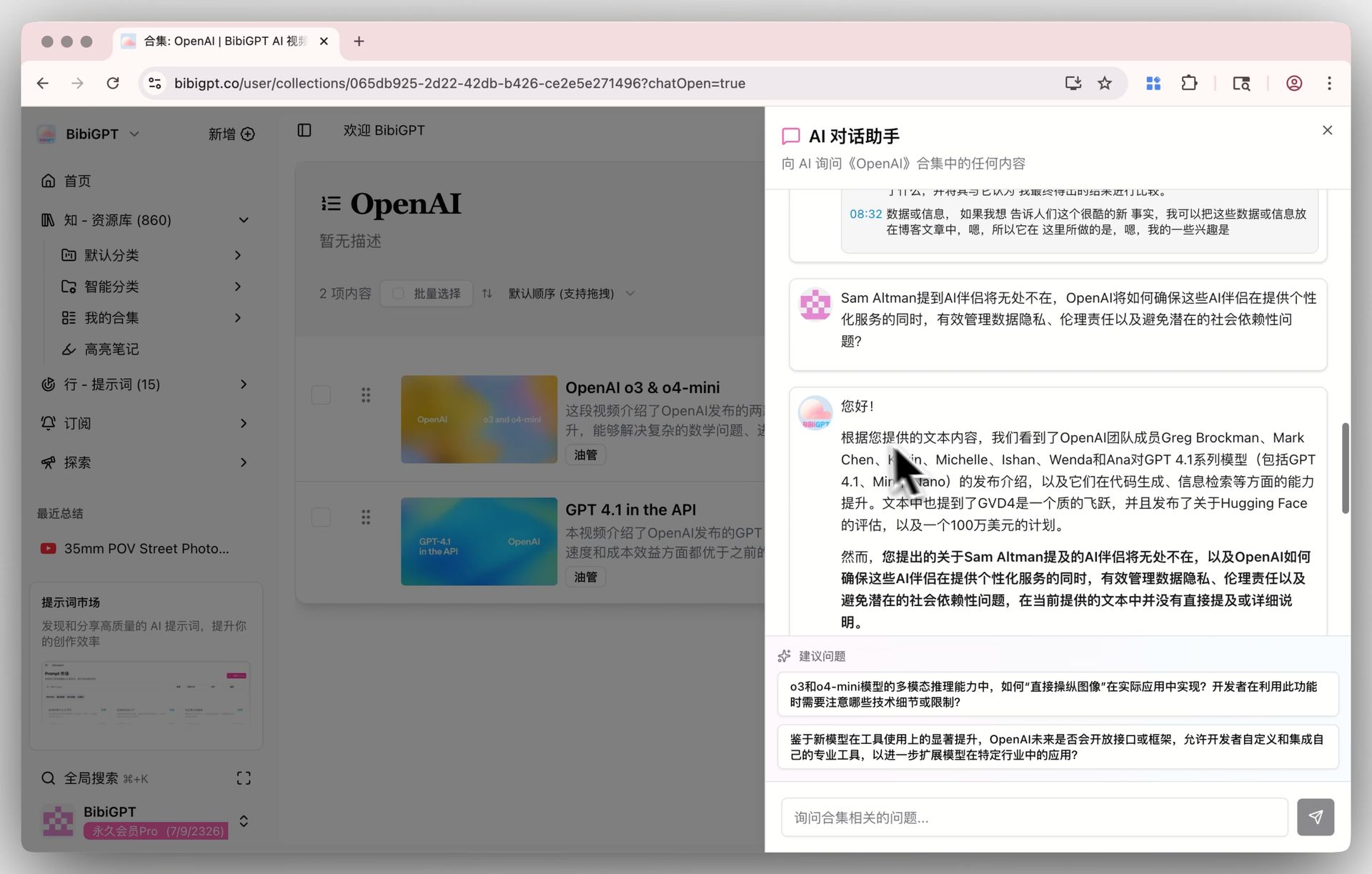 合集 AI 对话
合集 AI 对话
2. 自定义提示词:一份视频多种产出
同一份会议录音,用不同提示词生成:"决议纪要"、"行动项清单"、"给团队的邮件草稿"、"给老板的一页汇报"。原本需要反复 GPT 复制粘贴的流程,一次搞定。
3. 外部视频原生支持
B 站、YouTube、小红书、小宇宙、抖音、TikTok 粘贴链接直接处理,这是 AI 好记不覆盖的核心场景。
4. Obsidian / Notion / 飞书联动
桌面端自动写入本地 Obsidian Vault,配合反链图谱形成可生长的知识网络。适合重度 PKM 用户。
六、FAQ
Q1: AI 好记的优势是什么?
专精会议场景 + 中文会议纪要结构化(议题/决议/待办)做得更贴近国内职场习惯。如果你是每天开会 3-5 场的项目经理 / HR,AI 好记的会议模板可能开箱即用。
Q2: BibiGPT 能替代 AI 好记做会议笔记吗?
能。用 BibiGPT 的自定义提示词设置"会议纪要格式"模板,一次配置后续所有会议录音都按此结构出。外加会议之外的 B 站/YouTube/播客场景也一并覆盖。
Q3: 两个都用可以吗?
完全可以——AI 好记专做公司内会议,BibiGPT 专做外部内容消费,互不冲突。但多数职场人会选一个主力工具,避免笔记分散在两个平台。
Q4: BibiGPT 支持实时录音吗?
BibiGPT 桌面端支持本地音频文件上传处理,实时录音会议场景优先推荐配合系统级录音工具(macOS Screen Recording / Windows 录音机)录好后上传。
Q5: 会议内容涉及公司机密,数据安全怎么保障?
BibiGPT 提供企业版 + 私有链接模式,可以本地化部署或走私有化处理。普通订阅用户的内容也可设置为私有。详见企业版页面。
Q6: 中英文混合会议能识别吗?
BibiGPT 的语音识别支持中英混合(code-switching)识别,对外企、跨境团队友好。AI 好记也在完善多语言但主要优势仍在中文。
Q7: 价格哪个便宜?
根据你的使用量。短期 / 低频用户:两者的免费额度都够用;高频用户:需要根据你的会议时长 vs 视频数量选订阅类型。BibiGPT 的 Plus 按月订阅 + 按需充值灵活度较高。
立即试用:同时体验两种场景
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
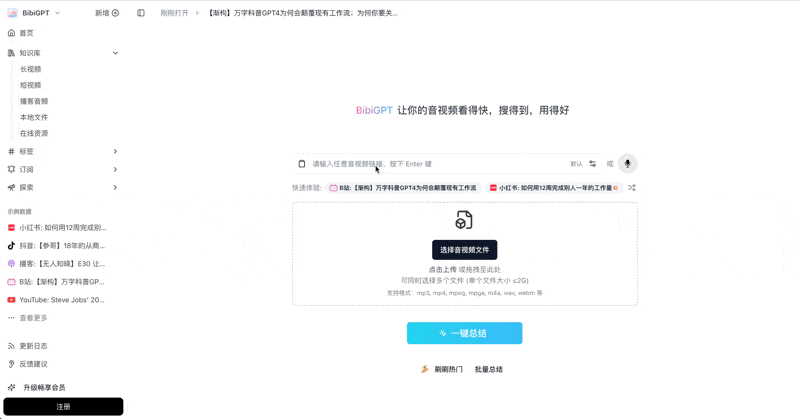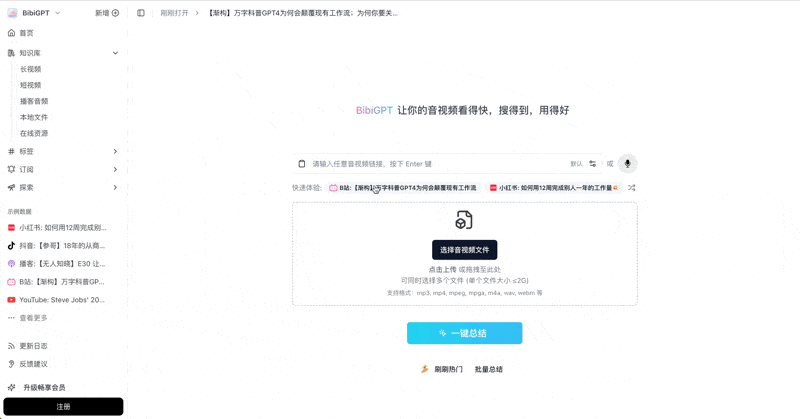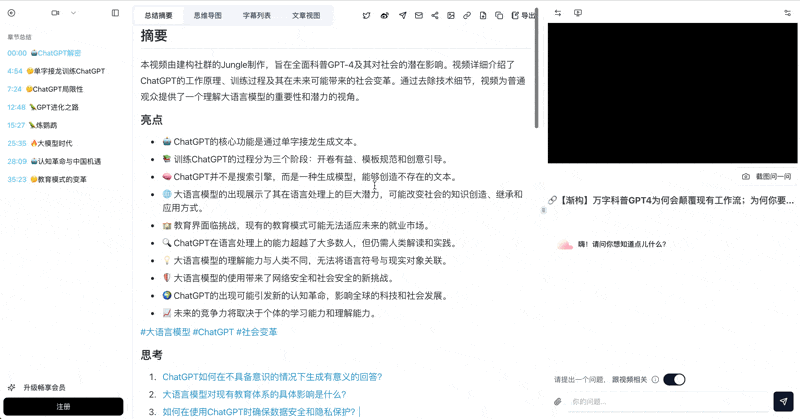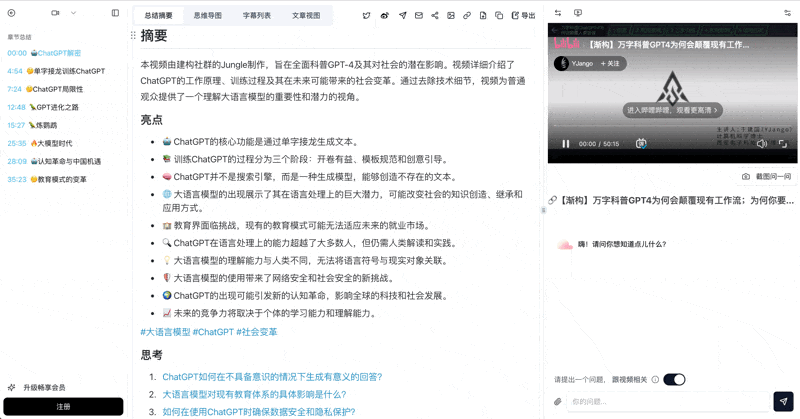
看个实际例子——把一场 30 分钟的会议录音交给 BibiGPT 会变成什么样?
See BibiGPT's AI Summary in Action
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Free相关阅读:
核心功能:自定义提示词总结、合集 AI 对话、Obsidian 自动保存。
BibiGPT 团队