AI学习看板:用AI课件增强把网课变成你的专属复习系统
你有没有这样的经历?花两小时看完一节网课,笔记只记了三行;考试前翻回去复习,发现关键的那张图表早已记不清长什么样。
在线学习最大的瓶颈不是"找不到好课",而是看完之后留不住。传统的学习方式——暂停截图、手动笔记、反复拖进度条——不仅效率低下,更让学习变成了一场体力活。
2026 年,AI 学习看板正在改变这一切。通过将网课视频中的在线课程幻灯片自动提取、用 AI 课件增强重新设计、再生成结构化复习卡片,BibiGPT 让你的学习效率工具升级到一个全新维度。
See BibiGPT's AI Summary in Action
Bilibili: GPT-4 & Workflow Revolution
A deep-dive explainer on how GPT-4 transforms work, covering model internals, training stages, and the societal shift ahead.
总结
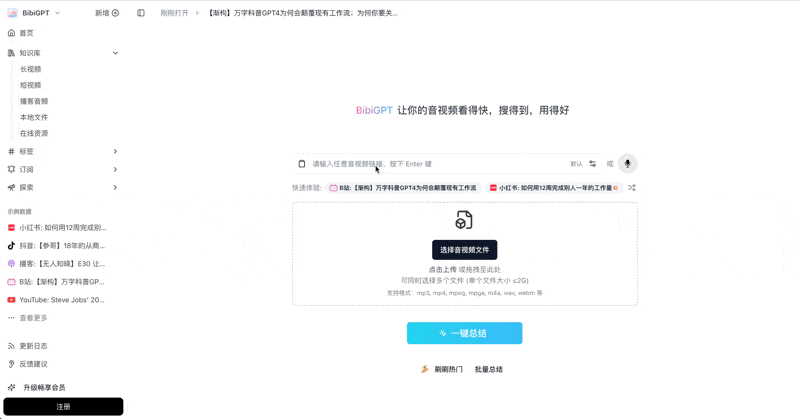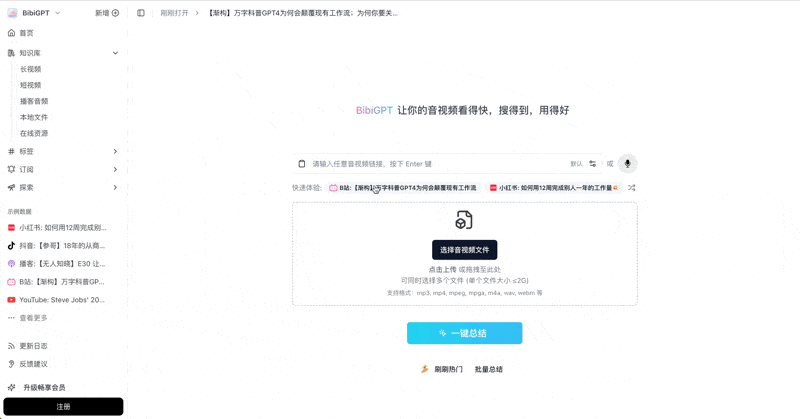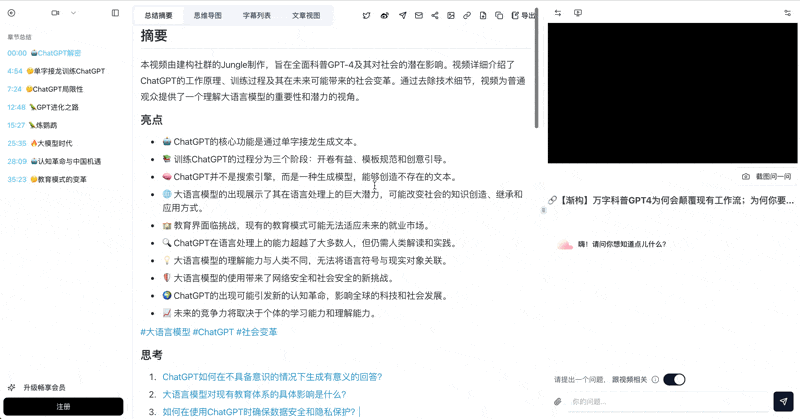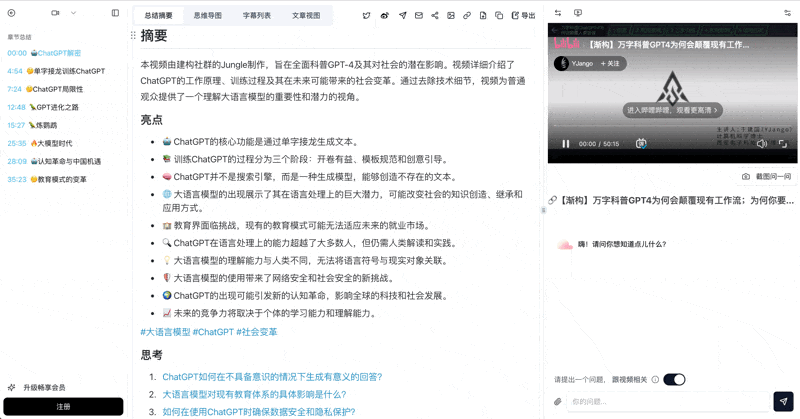
本视频深入浅出地科普了ChatGPT的底层原理、三阶段训练过程及其涌现能力,并探讨了大型语言模型对社会、教育、新闻和内容生产等领域的深远影响。作者强调,ChatGPT的革命性意义在于验证了大型语言模型的可行性,预示着未来将有更多更强大的模型普及,从而改变人类群体协作中知识的创造、继承和应用方式,并呼吁个人和国家积极应对这一技术浪潮。
亮点
- 💡 核心原理揭秘: ChatGPT的本质功能是"单字接龙",通过"自回归生成"来构建长篇回答,其训练旨在学习举一反三的通用规律,而非简单记忆,这使其与搜索引擎截然不同。
- 🧠 三阶段训练: 大型语言模型经历了"开卷有益"(预训练)、"模板规范"(监督学习)和"创意引导"(强化学习)三个阶段,使其从海量知识的"懂王鹦鹉"进化为既懂规矩又会试探的"博学鹦鹉"。
- 🚀 涌现能力: 当模型规模达到一定程度时,会突然涌现出理解指令、理解例子和思维链等惊人能力,这些是小模型所不具备的。
- 🌍 社会影响深远: 大型语言模型将极大提升人类群体协作中知识处理的效率,其影响范围堪比电脑和互联网,尤其对教育、学术、新闻和内容生产行业带来颠覆性变革。
- 🛡️ 应对未来挑战: 面对技术带来的混淆、安全风险和结构性失业等问题,个人应克服抵触心理,重塑终身学习能力;国家则需自主研发大模型,并推动教育改革和科技伦理建设。
#ChatGPT #大型语言模型 #人工智能 #未来工作流 #终身学习
思考
- ChatGPT与传统搜索引擎有何本质区别?
- ChatGPT是一个生成模型,它通过学习语言规律和知识来“创造”新的文本,其结果是根据模型预测逐字生成的,不直接从数据库中搜索并拼接现有信息。而搜索引擎则是在庞大数据库中查找并呈现最相关的内容。
- 为什么说大语言模型对教育界的影响尤其强烈?
- 大语言模型能够高效地继承和应用既有知识,这意味着未来许多学校传授的知识,任何人都可以通过大语言模型轻松获取。这挑战了以传授既有知识为主的现代教育模式,迫使教育体系加速向培养学习能力和创造能力转型,以适应未来就业市场的需求。
- 个人应该如何应对大语言模型带来的社会变革?
- 首先,要克服对新工具的抵触心理,积极拥抱并探索其优点和缺点。其次,必须做好终身学习的准备,重塑自己的学习能力,掌握更高抽象层次的认知方法,因为未来工具更新换代会越来越快,学习能力将是应对变革的根本。
术语解释
- 单字接龙 (Single-character Autoregressive Generation): ChatGPT的核心功能,指模型根据已有的上文,预测并生成下一个最有可能的字或词,然后将新生成的字词与上文组合成新的上文,如此循环往复,生成任意长度的文本。
- 涌现能力 (Emergent Abilities): 指当大语言模型的规模(如参数量、训练数据量)达到一定程度后,突然展现出在小模型中未曾察觉到的新能力,例如理解指令、语境内学习(理解例子)和思维链推理等。
- 预训练 (Pre-training): 大语言模型训练的第一阶段,通常称为“开卷有益”,模型通过对海量无标注文本数据进行单字接龙等任务,学习广泛的语言知识、世界信息和语言规律。
- 监督学习 (Supervised Learning): 大语言模型训练的第二阶段,通常称为“模板规范”,模型通过学习人工标注的优质对话范例,来规范其回答的对话模式和内容,使其符合人类的期望和价值观。
- 强化学习 (Reinforcement Learning): 大语言模型训练的第三阶段,通常称为“创意引导”,模型根据人类对它生成答案的评分(奖励或惩罚)来调整自身,以引导其生成更具创造性且符合人类认可的回答。
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Free传统网课笔记提取为什么不够用?
大多数人在看网课时的工作流是这样的:播放视频 → 看到重要内容 → 暂停 → 截图或手抄 → 继续播放。这种方式至少有三个痛点:
1. 信息遗漏严重
讲师一张PPT可能只停留30秒,你还没来得及理解就翻页了。手动截图永远跟不上讲课节奏,漏掉的往往是最关键的信息。
2. 截图质量参差不齐
网课画面经过视频压缩,截图往往模糊、有水印、排版混乱。很多讲师的PPT本身设计也不够清晰——密密麻麻的文字堆在一起,复习时根本看不进去。
3. 缺乏结构化组织
几十张散落在相册里的截图,没有标题、没有分类、没有上下文。两周后再打开,你已经忘了哪张图对应哪个知识点。
AI学习看板如何工作:从网课到复习卡片的完整流程
BibiGPT 的 Slide Mode(幻灯片模式)不只是截图工具,而是一套完整的网课笔记提取与 AI 课件增强系统。它的工作流程分为三步:
第一步:智能幻灯片提取
粘贴网课链接(支持 B站、YouTube、Coursera、网易公开课等主流平台),BibiGPT 会自动分析视频画面,精准识别每一张幻灯片的切换时刻,提取完整的课件画面。不需要手动暂停,不需要逐帧截图——AI 帮你把整节课的所有关键画面一次性提取出来。
第二步:AI 课件增强与重新设计
这是最让人惊喜的环节。提取出来的原始画面可能模糊、排版混乱、视觉效果差。BibiGPT 的 AI 会自动对每张幻灯片进行增强处理:
- 清晰化处理:去除视频压缩伪影,提升文字和图表的可读性
- 智能排版:重新组织内容布局,让信息层次分明
- 视觉优化:统一配色和字体风格,生成专业级演示文稿
原本讲师随手做的课件,经过 AI 增强后变成了设计感十足的学习材料。
第三步:生成学习看板与复习卡片
所有增强后的幻灯片会被组织成一个结构化的学习看板——按课程章节排列,每张卡片包含关键信息摘要和时间戳定位。你可以像翻阅闪记卡一样快速复习,也可以点击任意卡片跳转到原视频的对应时刻深入理解。
BibiGPT vs 传统笔记工具:学习效率工具的代际跨越
你可能会问:Notion、Anki、OneNote 不也能做笔记吗?是的,但它们解决的是"记录"问题,而 BibiGPT 的 AI 学习看板解决的是"从视频中提取+增强+组织"的完整链路。
| 维度 | Notion / OneNote | Anki | BibiGPT AI学习看板 |
|---|
| 内容来源 | 手动输入/粘贴 | 手动制卡 | 视频自动提取 |
| 幻灯片提取 | 不支持 | 不支持 | AI 自动识别切换点 |
| 画面增强 | 不支持 | 不支持 | AI 重新设计课件 |
| 复习方式 | 自由浏览 | 间隔重复 | 看板浏览+时间戳回溯 |
| 上手成本 | 需要学习模板 | 需要手动制卡 | 粘贴链接即可 |
| 与原视频联动 | 无 | 无 | 点击跳转到对应时刻 |
关键区别在于:传统工具需要你先"消费"完内容再手动整理,而 BibiGPT 在你"消费"内容的同时就完成了提取、增强和组织。你的时间不再花在低价值的搬运工作上,而是直接进入高价值的理解和记忆环节。
想了解更多关于视频转幻灯片的技术细节,可以阅读这篇指南:视频转幻灯片 AI PPT 生成器完整指南。
BibiGPT Slide Mode Preview10 slides video-to-slides-ai-ppt-maker.demoSlides.0.title
video-to-slides-ai-ppt-maker.demoSlides.0.body
video-to-slides-ai-ppt-maker.demoSlides.0.accent
Turn any video into slides
Extract, enhance, and export slides with AI
学习场景全覆盖:从 MOOC 到考试冲刺
AI 学习看板的应用场景远不止看网课。以下是几个典型使用场景:
MOOC 平台课程(Coursera、edX、中国大学MOOC)
大型在线课程通常有数十节视频,每节课信息量巨大。用 BibiGPT 批量提取所有课件幻灯片,生成完整的课程知识图谱,期末复习时一目了然。
YouTube 教程与技术讲座
编程教程、设计教程、TED 演讲……YouTube 上的优质内容往往缺乏配套讲义。BibiGPT 帮你把视频内容变成可搜索、可复习的结构化笔记,配合 AI 学习指南工具 生成个性化学习路径。
考试冲刺复习
CPA、法考、考研……备考期间最需要的是高效的复习材料。把培训课视频转成 AI 增强的幻灯片卡片,配合间隔重复策略,记忆效率远超反复观看视频。
会议录像与培训回放
企业内部培训、行业峰会录像同样适用。用 BibiGPT 提取演示文稿关键页面,生成会议纪要级别的结构化输出。更多相关场景可以查看会议视频转 PPT 报告指南。
最大化 AI 课件增强学习效率的 5 个技巧
掌握以下技巧,可以让你的 AI 学习看板发挥最大价值:
1. 先看 AI 总结,再看幻灯片
BibiGPT 同时提供视频的 AI 摘要总结。建议先快速浏览总结了解课程框架,再逐张查看增强后的幻灯片,这样理解效率会高很多。
2. 善用时间戳回溯
遇到不理解的幻灯片内容,点击时间戳直接跳转到原视频对应位置。不需要从头找,3 秒定位到讲解片段。
3. 搭配 AI 对话追问
看完幻灯片后有疑问?直接用 BibiGPT 的 AI 对话功能向视频内容提问,获得基于原始内容的精准回答。
4. 批量处理课程系列
不要一节一节地处理,把整个课程播放列表一次性导入,BibiGPT 会批量生成所有课程的幻灯片和学习看板。
5. 导出到你习惯的工具
增强后的幻灯片支持导出为 PDF 和 PPT 格式,可以无缝导入 Notion、Obsidian 等你已有的知识管理系统,与你的学习工作流完美衔接。详细的视频转文档方案可以参考 AI 会议视频转文档功能。
从"看视频"到"拥有知识":学习效率工具的终局
网课笔记提取和 AI 课件增强不是锦上添花的功能,而是学习方式的根本升级。当 AI 帮你完成了提取、增强、组织这些机械性工作,你的全部精力都可以集中在真正重要的事情上——理解、思考和运用。
BibiGPT 的 AI 学习看板,就是这个时代学生、考生和终身学习者最需要的学习效率工具。
立即体验 BibiGPT,把你的下一节网课变成专属学习看板:
See BibiGPT's AI Summary in Action
Bilibili: GPT-4 & Workflow Revolution
A deep-dive explainer on how GPT-4 transforms work, covering model internals, training stages, and the societal shift ahead.
总结
本视频深入浅出地科普了ChatGPT的底层原理、三阶段训练过程及其涌现能力,并探讨了大型语言模型对社会、教育、新闻和内容生产等领域的深远影响。作者强调,ChatGPT的革命性意义在于验证了大型语言模型的可行性,预示着未来将有更多更强大的模型普及,从而改变人类群体协作中知识的创造、继承和应用方式,并呼吁个人和国家积极应对这一技术浪潮。
亮点
- 💡 核心原理揭秘: ChatGPT的本质功能是"单字接龙",通过"自回归生成"来构建长篇回答,其训练旨在学习举一反三的通用规律,而非简单记忆,这使其与搜索引擎截然不同。
- 🧠 三阶段训练: 大型语言模型经历了"开卷有益"(预训练)、"模板规范"(监督学习)和"创意引导"(强化学习)三个阶段,使其从海量知识的"懂王鹦鹉"进化为既懂规矩又会试探的"博学鹦鹉"。
- 🚀 涌现能力: 当模型规模达到一定程度时,会突然涌现出理解指令、理解例子和思维链等惊人能力,这些是小模型所不具备的。
- 🌍 社会影响深远: 大型语言模型将极大提升人类群体协作中知识处理的效率,其影响范围堪比电脑和互联网,尤其对教育、学术、新闻和内容生产行业带来颠覆性变革。
- 🛡️ 应对未来挑战: 面对技术带来的混淆、安全风险和结构性失业等问题,个人应克服抵触心理,重塑终身学习能力;国家则需自主研发大模型,并推动教育改革和科技伦理建设。
#ChatGPT #大型语言模型 #人工智能 #未来工作流 #终身学习
思考
- ChatGPT与传统搜索引擎有何本质区别?
- ChatGPT是一个生成模型,它通过学习语言规律和知识来“创造”新的文本,其结果是根据模型预测逐字生成的,不直接从数据库中搜索并拼接现有信息。而搜索引擎则是在庞大数据库中查找并呈现最相关的内容。
- 为什么说大语言模型对教育界的影响尤其强烈?
- 大语言模型能够高效地继承和应用既有知识,这意味着未来许多学校传授的知识,任何人都可以通过大语言模型轻松获取。这挑战了以传授既有知识为主的现代教育模式,迫使教育体系加速向培养学习能力和创造能力转型,以适应未来就业市场的需求。
- 个人应该如何应对大语言模型带来的社会变革?
- 首先,要克服对新工具的抵触心理,积极拥抱并探索其优点和缺点。其次,必须做好终身学习的准备,重塑自己的学习能力,掌握更高抽象层次的认知方法,因为未来工具更新换代会越来越快,学习能力将是应对变革的根本。
术语解释
- 单字接龙 (Single-character Autoregressive Generation): ChatGPT的核心功能,指模型根据已有的上文,预测并生成下一个最有可能的字或词,然后将新生成的字词与上文组合成新的上文,如此循环往复,生成任意长度的文本。
- 涌现能力 (Emergent Abilities): 指当大语言模型的规模(如参数量、训练数据量)达到一定程度后,突然展现出在小模型中未曾察觉到的新能力,例如理解指令、语境内学习(理解例子)和思维链推理等。
- 预训练 (Pre-training): 大语言模型训练的第一阶段,通常称为“开卷有益”,模型通过对海量无标注文本数据进行单字接龙等任务,学习广泛的语言知识、世界信息和语言规律。
- 监督学习 (Supervised Learning): 大语言模型训练的第二阶段,通常称为“模板规范”,模型通过学习人工标注的优质对话范例,来规范其回答的对话模式和内容,使其符合人类的期望和价值观。
- 强化学习 (Reinforcement Learning): 大语言模型训练的第三阶段,通常称为“创意引导”,模型根据人类对它生成答案的评分(奖励或惩罚)来调整自身,以引导其生成更具创造性且符合人类认可的回答。
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Free